ECCV 2026 · CCF B · Accepted
Dynamic-V2C: Editable and Continual Vision-to-Concept Bottleneck Models via Influence Functions
中文项目页
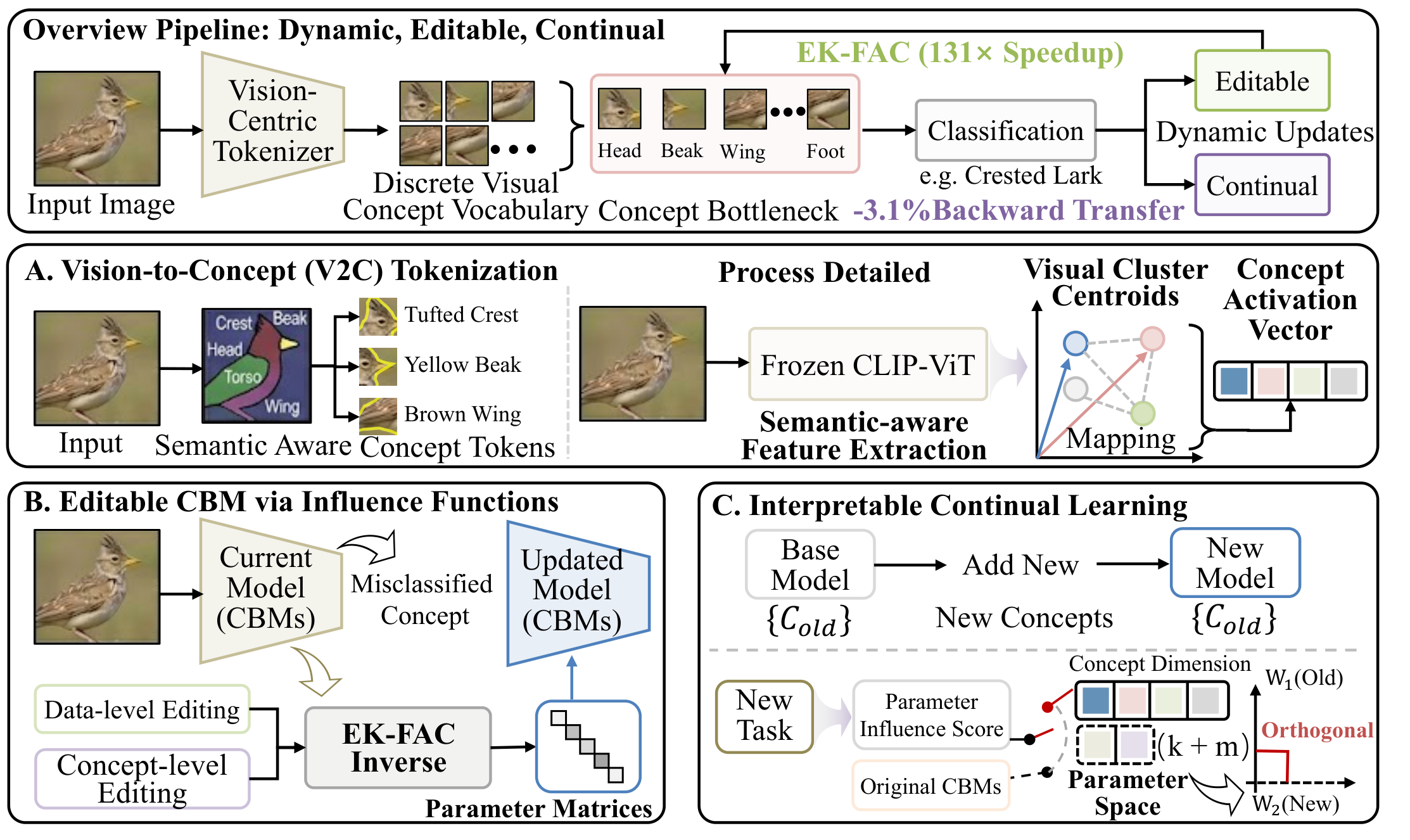
TL;DR
Dynamic-V2C 将 CBM 变成可编辑、可持续学习的视觉系统:用视觉落地的 V2C tokenization 表示概念,并用 influence-function 引擎支持快速模型编辑、伪相关调试、遗忘和概念词表扩展。
作者: Songning Lai, Shaofeng Liang, Jiayu Yang, Ninghui Feng, Yuxuan Fan, Wenshuo Chen
会议: European Conference on Computer Vision (ECCV 2026, CCF B), accepted
发布说明: 论文、引用和代码链接将在终稿(camera-ready)与开源制品(artifact release)流程完成后补充。
概览
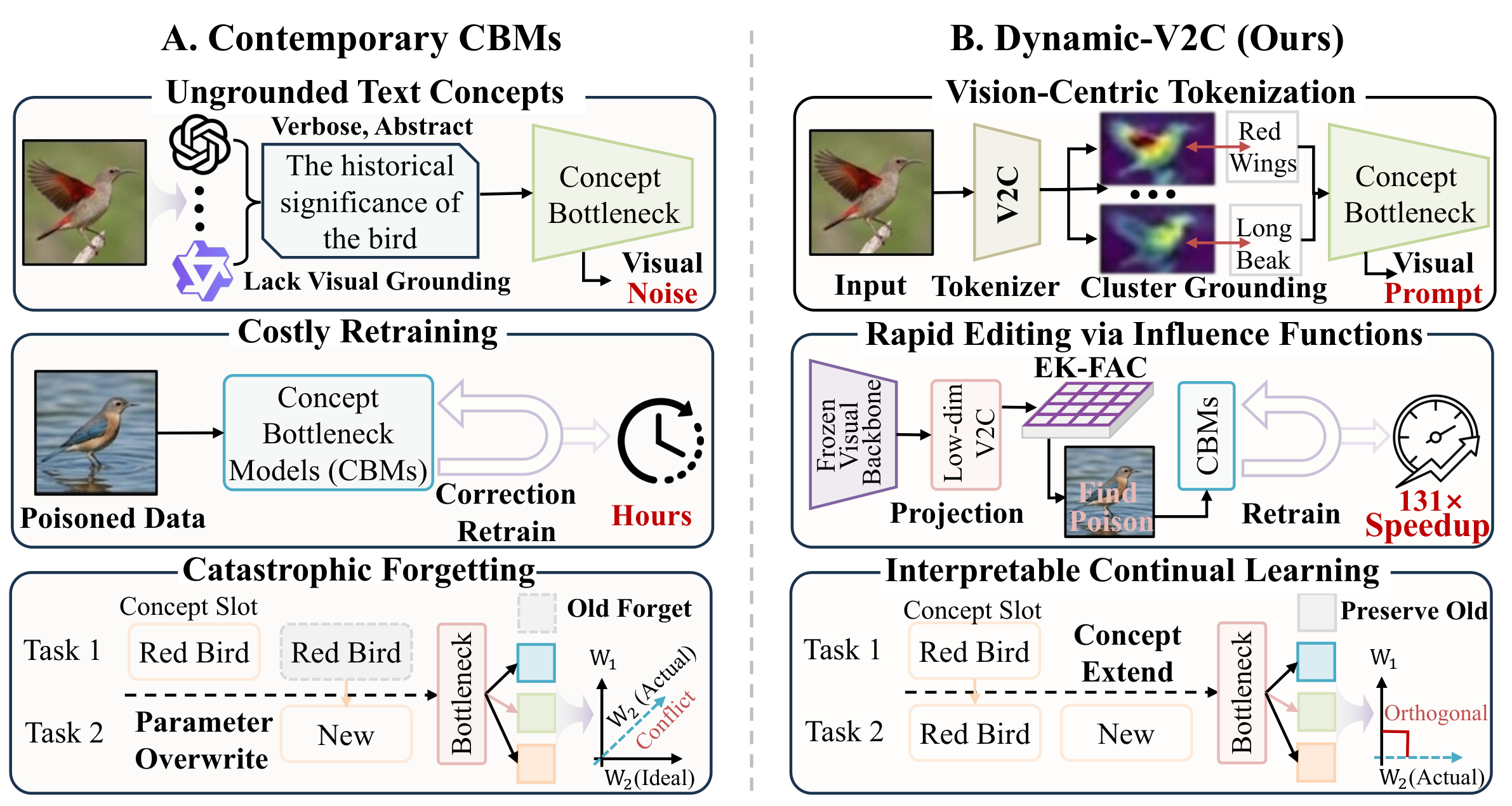
概念瓶颈模型(CBMs)通过人类可理解的概念路由预测,使模型决策可检查。然而,现有 CBM 在部署后维护困难:文本驱动概念可能缺乏视觉落地,伪相关通常需要完整重训才能修正,连续任务还可能覆盖已有概念知识。
Dynamic-V2C 用统一的可编辑与持续学习 Vision-to-Concept Bottleneck Model 解决这些限制。它构建视觉落地的概念 tokenizer,在低维概念瓶颈中应用 influence functions 实现无需重训的快速编辑,并在持续学习中扩展概念词表,同时保护历史概念。
方法
Dynamic-V2C 包含三个核心组件:
- Vision-to-Concept Tokenization: 将冻结视觉骨干网络的密集视觉特征投影到离散视觉概念词表,降低对抽象或非视觉 LLM 生成概念的依赖。
- Influence-Function Editing: 在瓶颈层内部计算近似 inverse-Hessian 更新,无需完整重训即可进行目标数据级遗忘和概念级调试。
- Interpretable Continual Learning: 当新任务无法由已有词表表示时加入新视觉概念,并用 influence-guided 正交投影保护历史概念知识。
关键设计是将昂贵的曲率计算限制在紧凑的概念瓶颈内,使编辑路径足够快,适合部署后的定向修复,同时保留透明的概念层推理。
结果
Dynamic-V2C 在 CUB、CelebA、OAI 和 Split-CIFAR100 上评估,关注预测效用、模型编辑速度、伪相关调试、面向隐私的输出级遗忘和持续学习。
快速数据级编辑
| 数据集 | 编辑目标 | Dynamic-V2C 效用 | Dynamic-V2C 运行时间 |
|---|---|---|---|
| CUB | 数据级遗忘 | 0.7963 ± 0.003 F1 | 39s |
| OAI | 数据级遗忘 | 0.8808 ± 0.002 F1 | 141s |
在 CUB 上,Dynamic-V2C 将完整重训所需的 5133 秒编辑时间降低到 39 秒,约 131× 更快,同时保持相当的效用。
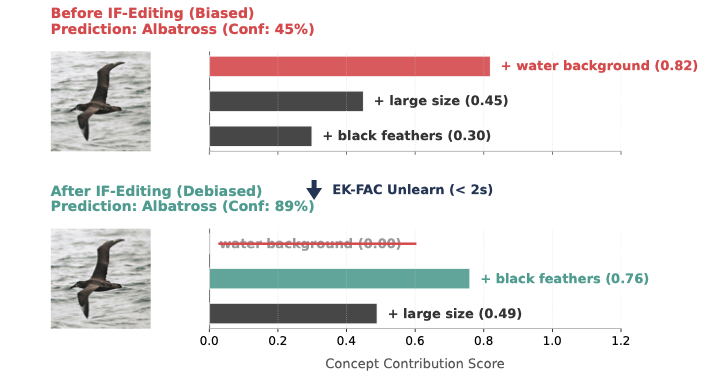
伪相关调试
| 设置 | 平均准确率 | 最差组准确率 | 运行时间 |
|---|---|---|---|
| CelebA 性别调试 | 94.0 ± 0.2 | 81.5 ± 0.7 | < 2s |
Dynamic-V2C 识别导致伪相关行为的训练样本和概念路径,并通过 influence-function 更新抑制这些路径,无需重训整个模型。
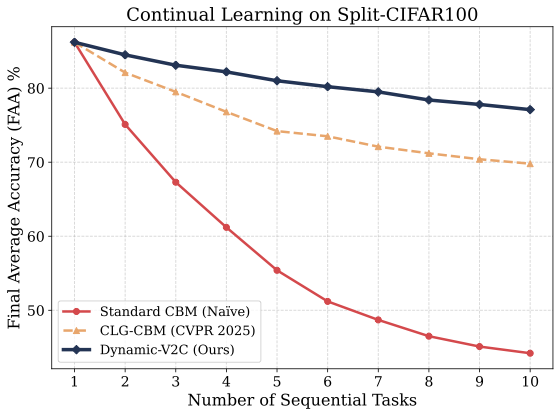
持续概念学习
| 设置 | 最终平均准确率 | 反向迁移 |
|---|---|---|
| Split-CIFAR100(10 个任务) | 78.5 ± 0.6 | -3.1 ± 0.4 |
持续学习结果表明,Dynamic-V2C 能够为新任务扩展概念词表,并显著减少灾难性遗忘。
概念可视化
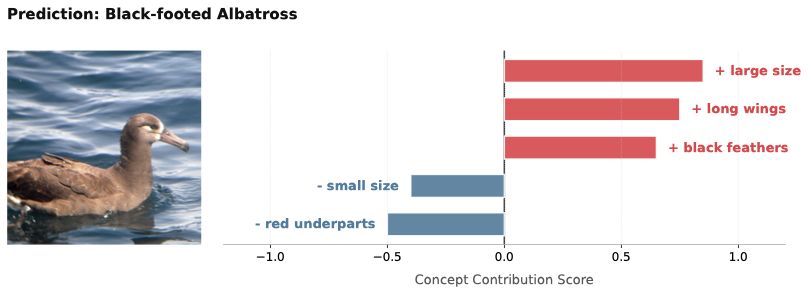
Dynamic-V2C 将预测落地到可检查的视觉概念中。定性示例展示了细粒度鸟类识别和人脸属性预测中的概念贡献,使正向与负向概念证据都更加明确。
发布
论文已被 ECCV 2026 接收。公开 PDF、引用元数据和代码仓库链接将在终稿(camera-ready)与开源制品(artifact release)流程就绪后补充。