ECCV 2026 · CCF B · Accepted
Dynamic-V2C: Editable and Continual Vision-to-Concept Bottleneck Models via Influence Functions
Official project page
TL;DR
Dynamic-V2C turns Concept Bottleneck Models into editable and continual visual systems by combining visually grounded V2C tokenization with an influence-function engine for fast model editing, spurious concept debugging, unlearning, and concept vocabulary expansion.
Authors: Songning Lai, Shaofeng Liang, Jiayu Yang, Ninghui Feng, Yuxuan Fan, Wenshuo Chen
Venue: European Conference on Computer Vision (ECCV 2026, CCF B), accepted
Release note: Paper, citation, and code links will be added after the public camera-ready and artifact-release process is finalized.
Overview
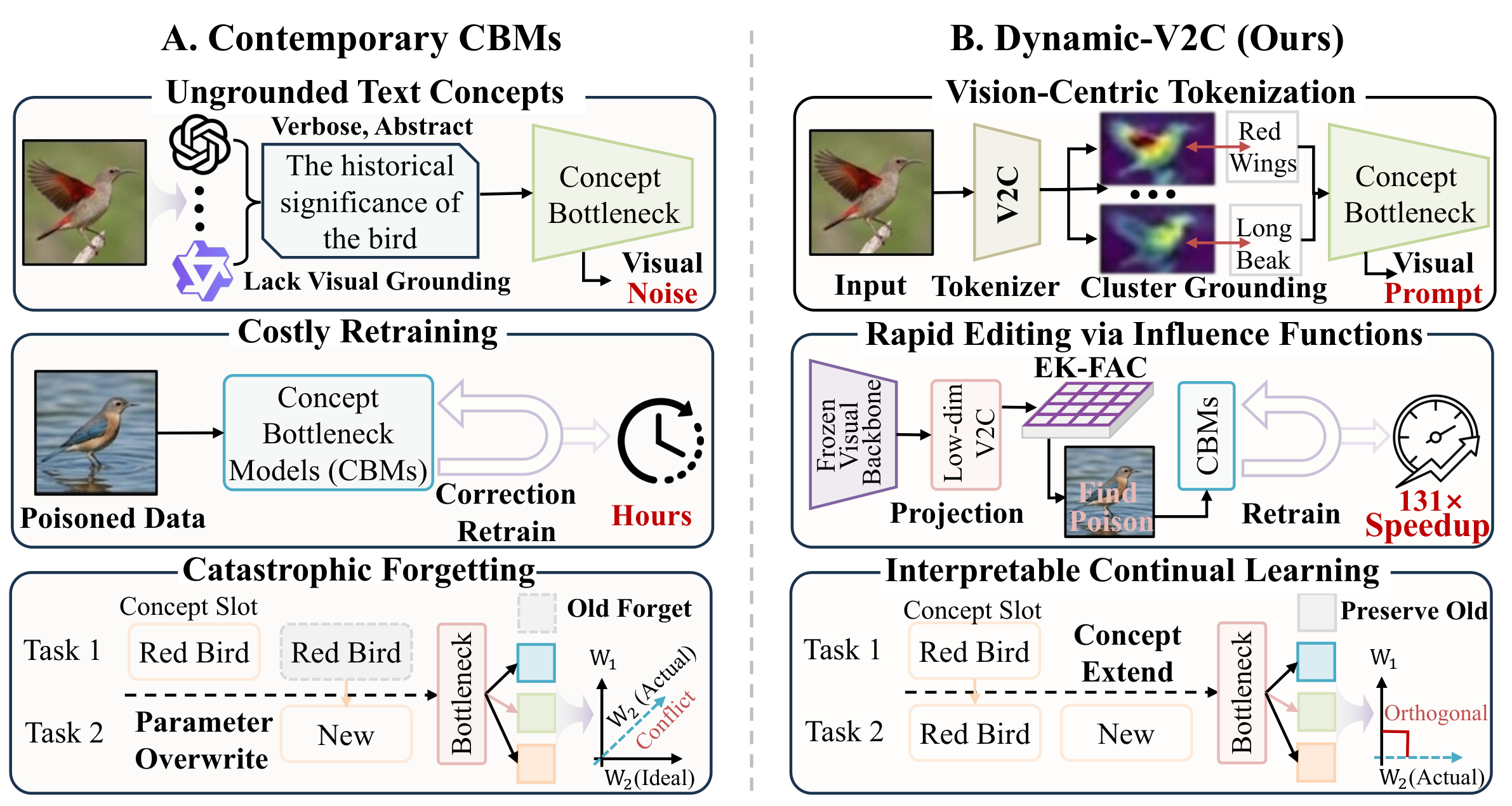
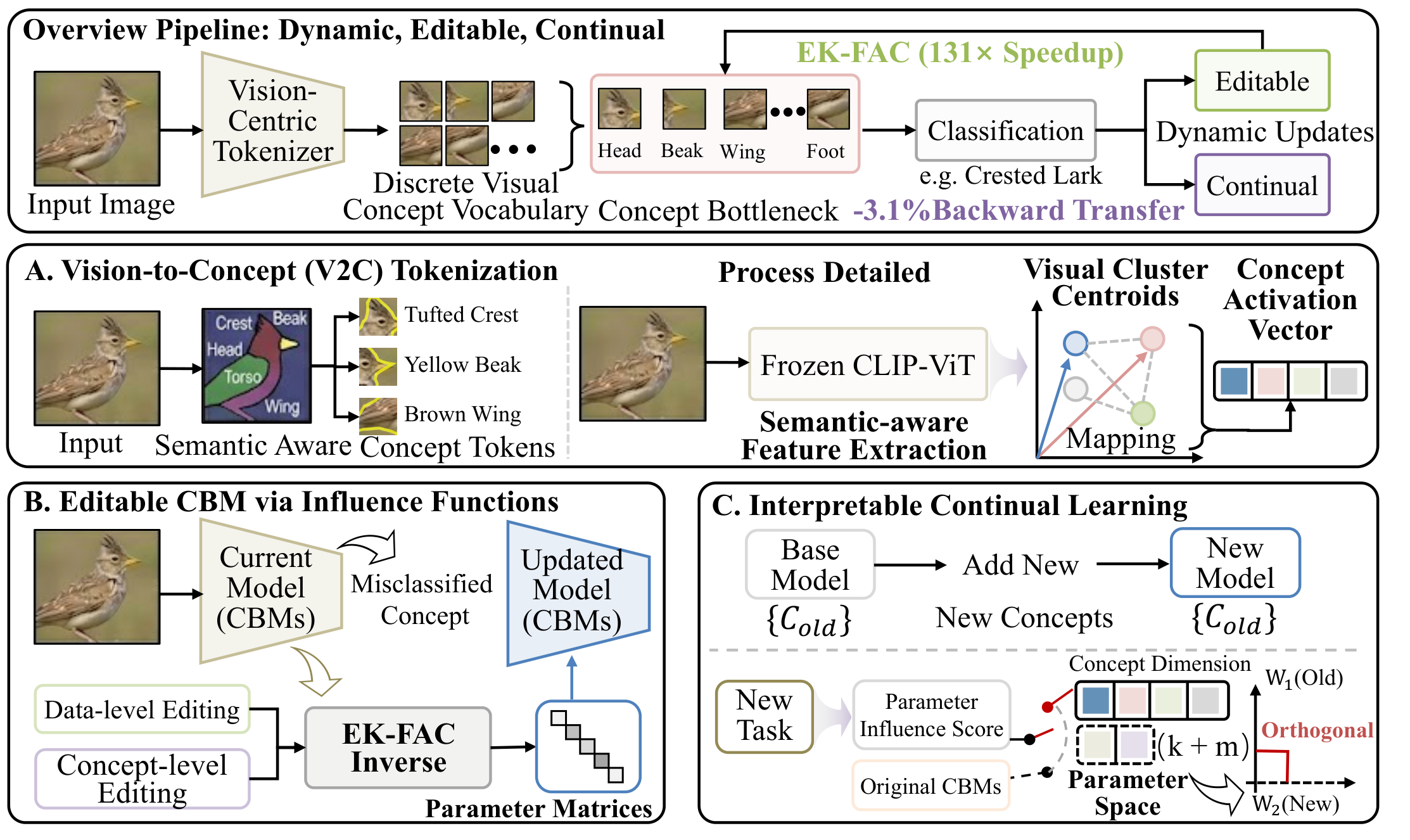
Concept Bottleneck Models (CBMs) make model decisions inspectable by routing predictions through human-understandable concepts. Current CBMs, however, are difficult to maintain after deployment: text-driven concepts can be visually ungrounded, spurious correlations often require full retraining to correct, and sequential tasks can overwrite previous concept knowledge.
Dynamic-V2C addresses these limitations with a unified editable and continual Vision-to-Concept Bottleneck Model. It builds a visually grounded concept tokenizer, applies influence functions in the low-dimensional concept bottleneck for rapid retraining-free edits, and expands the concept vocabulary during continual learning while protecting historical concepts.
Method
Dynamic-V2C is organized around three components:
- Vision-to-Concept Tokenization: dense visual features from a frozen vision backbone are projected into a discrete visual concept vocabulary, reducing reliance on abstract or non-visual LLM-generated concepts.
- Influence-Function Editing: the model computes approximate inverse-Hessian updates inside the bottleneck layer, enabling targeted data-level unlearning and concept-level debugging without full retraining.
- Interpretable Continual Learning: new visual concepts are added when new tasks cannot be represented by the existing vocabulary, while influence-guided orthogonal projections protect historical concept knowledge.
The key design choice is to restrict expensive curvature computation to the compact concept bottleneck. This keeps the editing path fast enough for targeted post-deployment repair while preserving transparent concept-level reasoning.
Results
Dynamic-V2C is evaluated on CUB, CelebA, OAI, and Split-CIFAR100. The experiments focus on predictive utility, model editing speed, spurious correlation debugging, privacy-oriented output-level unlearning, and continual learning.
Fast Data-Level Editing
| Dataset | Editing Target | Dynamic-V2C Utility | Dynamic-V2C Runtime |
|---|---|---|---|
| CUB | Data-level unlearning | 0.7963 ± 0.003 F1 | 39s |
| OAI | Data-level unlearning | 0.8808 ± 0.002 F1 | 141s |
On CUB, Dynamic-V2C reduces editing time from 5133s for full retraining to 39s, approximately 131× faster while preserving comparable utility.
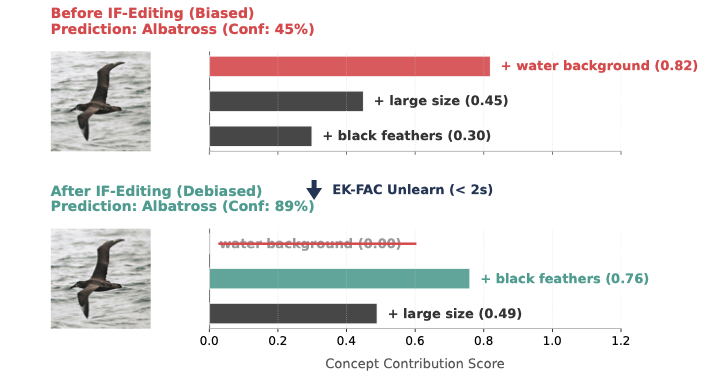
Spurious Correlation Debugging
| Setting | Average Accuracy | Worst-Group Accuracy | Runtime |
|---|---|---|---|
| CelebA gender debugging | 94.0 ± 0.2 | 81.5 ± 0.7 | < 2s |
Dynamic-V2C identifies influential training samples and concept routes responsible for spurious behavior, then applies an influence-function update to suppress those routes without retraining the full model.
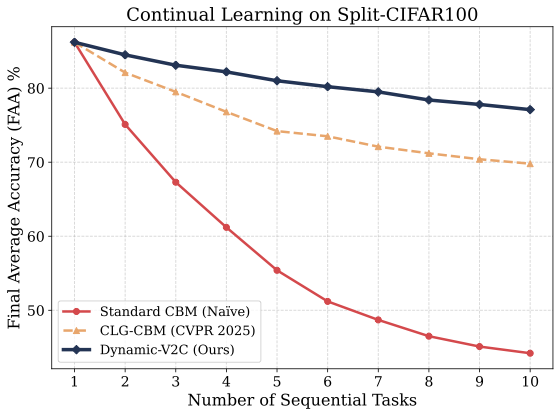
Continual Concept Learning
| Setting | Final Average Accuracy | Backward Transfer |
|---|---|---|
| Split-CIFAR100, 10 tasks | 78.5 ± 0.6 | -3.1 ± 0.4 |
The continual-learning results show that Dynamic-V2C can expand its concept vocabulary for new tasks while sharply reducing catastrophic forgetting.
Concept Visualization
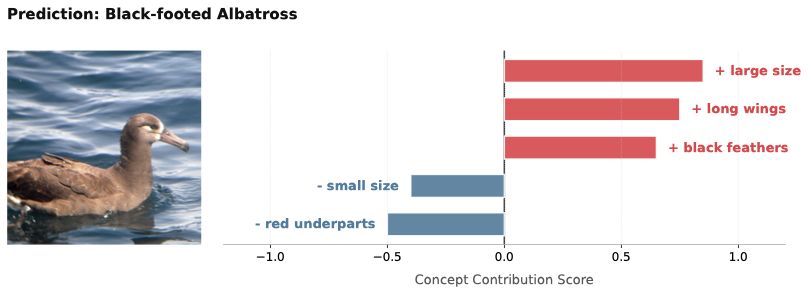
Dynamic-V2C grounds predictions in visually inspectable concepts. The qualitative examples show concept contributions for fine-grained bird recognition and facial-attribute prediction, making both positive and negative concept evidence explicit.
Release
The paper has been accepted to ECCV 2026. Public PDF, citation metadata, and repository links will be added here after the camera-ready and artifact-release process is ready.