TMLR 2026 · Accepted
Multimodal Deception in Explainable AI: Concept-Level Backdoor Attacks on Concept Bottleneck Models
中文项目页
TL;DR
我们揭示并优化了针对 CBM 的概念层后门攻击(CAT/CAT+),在保持干净样本性能的同时获得高攻击成功率,并通过 Image2Trigger_c 验证端到端可行性。
标题: Multimodal Deception in Explainable AI: Concept-Level Backdoor Attacks on Concept Bottleneck Models
作者: Songning Lai, Jiayu Yang, Yu Huang, Lijie Hu, Tianlang Xue, Zhangyi Hu, Jiaxu Li, Haicheng Liao, Zongyang Liu, Yutao Yue
链接: 论文 · 代码
概览
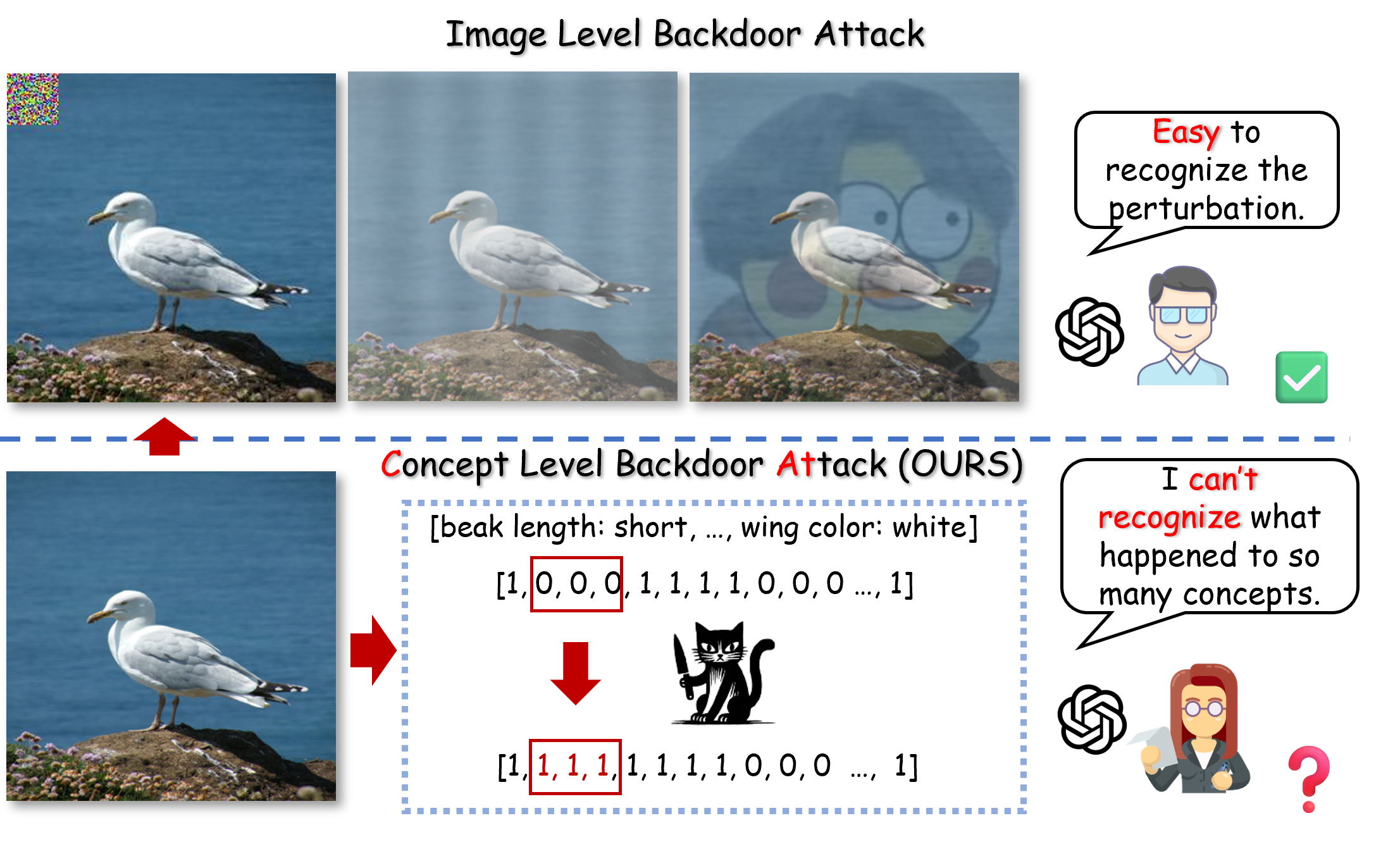
概念瓶颈模型(CBMs)通过人类可理解的概念来提升可解释性,但我们发现它们仍然容易受到隐蔽的后门操纵。我们提出 CAT 与 CAT+,面向概念表示进行攻击,同时尽量保持干净数据上的正常性能。
核心思想
- CAT 在训练阶段注入触发概念,并使用过滤策略,而不是随机破坏概念。
- CAT+ 进一步使用概念相关函数优化触发概念关联。
- 我们采用两阶段评估:
- 受控概念层脆弱性分析。
- 通过 Image2Trigger_c 进行端到端攻击验证。
主要结果
攻击有效性
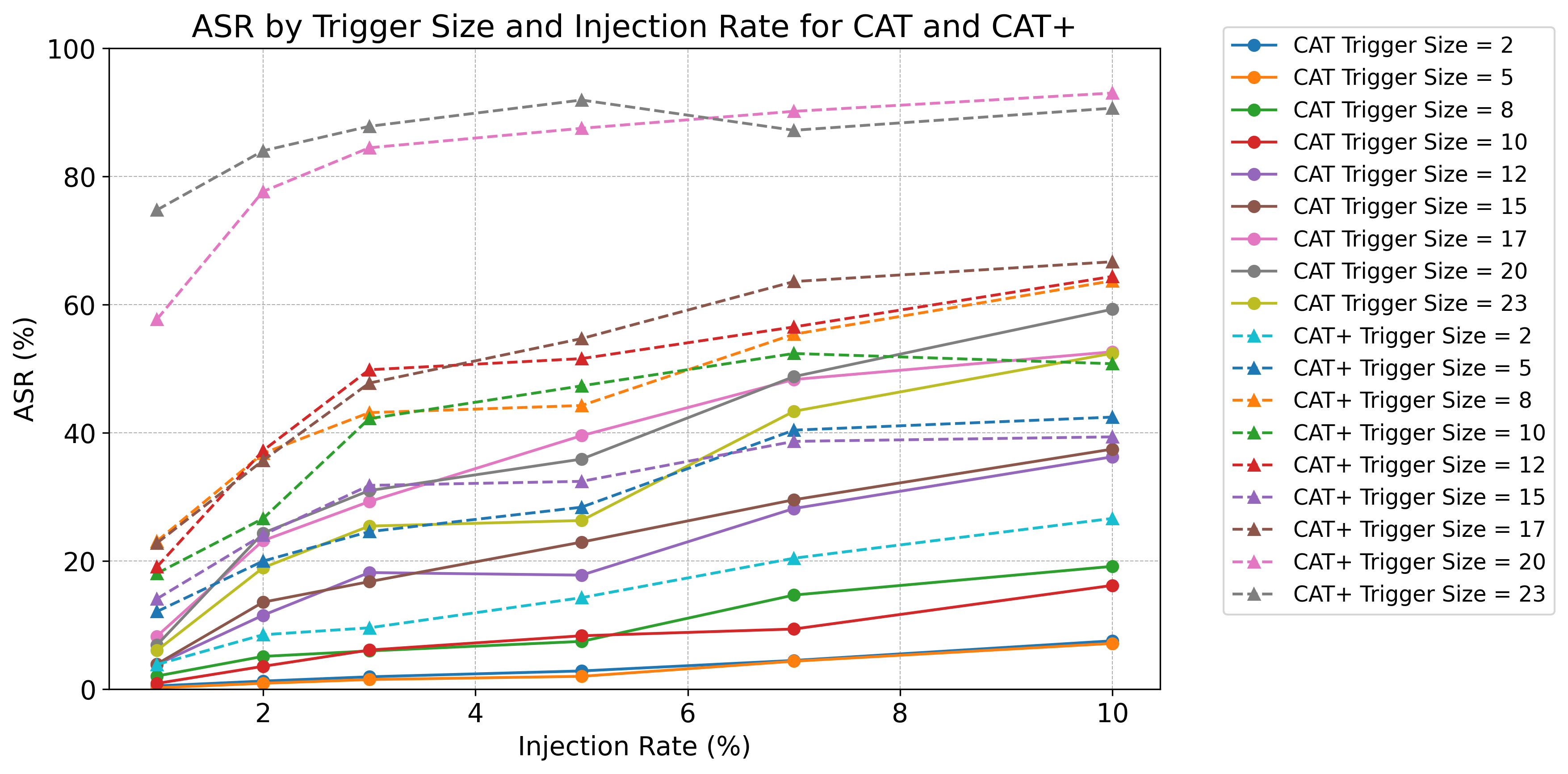
CAT/CAT+ 相比随机选择基线获得显著更高的攻击成功率,同时保持较强的干净样本性能。
端到端可行性

借助 Image2Trigger_c,概念层触发器操纵可以转换为实际图像空间攻击。
防御分析

Neural Cleanse 等传统防御方法难以检测这类语义后门模式。
开源代码
官方实现地址:
- 项目页:xll0328.github.io/cat
- 论文:OpenReview
- GitHub:xll0328/CAT_CBM-Backdoor
仓库包含:
- 干净 CBM 训练脚本;
- CAT / CAT+ 攻击实现;
- 随机触发器攻击基线;
- CUB 与 AwA2 的数据预处理。
摘要
深度学习在多个领域展现出变革性潜力,但其固有的不透明性推动了可解释人工智能(XAI)的发展。概念瓶颈模型(CBMs)通过人类可理解的概念约束模型表示,是 XAI 中的重要方向。然而,尽管 CBM 具有语义透明性,它们仍然容易受到后门攻击等安全威胁,即攻击者通过恶意操纵使模型在推理阶段出现受控错误行为。
CBM 利用视觉输入与文本概念的多模态表示增强可解释性,但这种双模态结构也引入了独特且尚未充分研究的攻击面。
为应对这一风险,我们提出 CAT(Concept-level Backdoor ATtacks),在训练过程中向概念表示注入隐蔽触发器。与随机破坏概念的朴素攻击不同,CAT 使用精细的过滤机制,在不显著损害干净样本性能的情况下实现精准预测操纵。我们进一步提出 CAT+,引入概念相关函数以迭代优化触发概念关联,从而提升攻击有效性和隐蔽性。
我们通过严格的两阶段评估框架验证方法。首先,在受控设置下证明概念瓶颈层的基本脆弱性,并显示 CAT+ 可获得高攻击成功率且与自然数据在统计上难以区分。其次,我们通过 Image2Trigger_c 展示端到端可行性,将视觉扰动转换为概念层触发器。大量实验表明 CAT 明显优于随机选择基线,而 Neural Cleanse 等标准防御难以检测这些语义攻击。
引用
@article{lai2026cat,
title={Multimodal Deception in Explainable AI: Concept-Level Backdoor Attacks on Concept Bottleneck Models},
author={Lai, Songning and Yang, Jiayu and Huang, Yu and Hu, Lijie and Xue, Tianlang and Hu, Zhangyi and Li, Jiaxu and Liao, Haicheng and Liu, Zongyang and Yue, Yutao},
journal={Transactions on Machine Learning Research},
year={2026}
}