TL;DR
SVCT 将概念增强 ViT 与去噪扩散平滑结合,在扰动下保持诊断准确率并输出稳定的概念层解释。
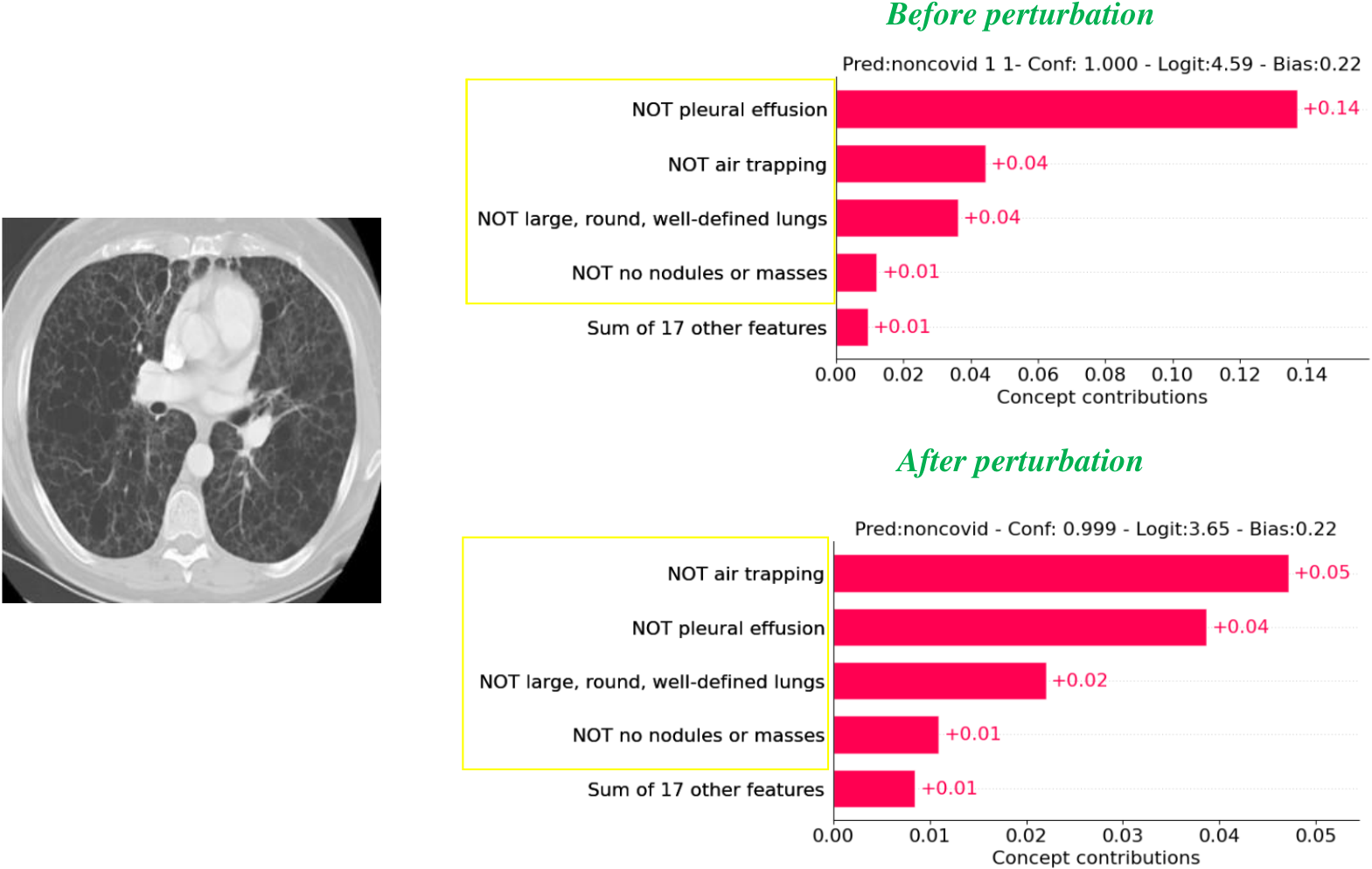
图 1:VCT 示例(OCT2017)
输入图像、无扰动概念输出和扰动后概念输出,展示为什么需要 SVCT 来获得稳定解释。

摘要
透明性是医疗 AI 的关键问题。概念瓶颈模型(CBMs)将潜空间限制为人类可理解的概念,但现有方法通常仅依赖概念特征进行预测,忽略医学图像中的内在特征嵌入,并且在输入扰动下不稳定。我们提出 Vision Concept Transformer (VCT),以 ViT 为骨干网络并使用 label-free 概念层,进一步融合概念特征与图像特征进行决策,以在保持可解释性的同时保留准确率。随后我们提出 Stable Vision Concept Transformer (SVCT),通过集成 Denoised Diffusion Smoothing (DDS) 使 top-k 概念索引和预测在扰动下保持稳定,从而提供忠实解释。四个医学数据集(HAM10000、Covid19-CT、BloodMNIST、OCT2017)上的实验表明,VCT 和 SVCT 保持了准确率与可解释性,且 SVCT 在扰动下提供稳定解释。
图 2:SVCT 框架概览
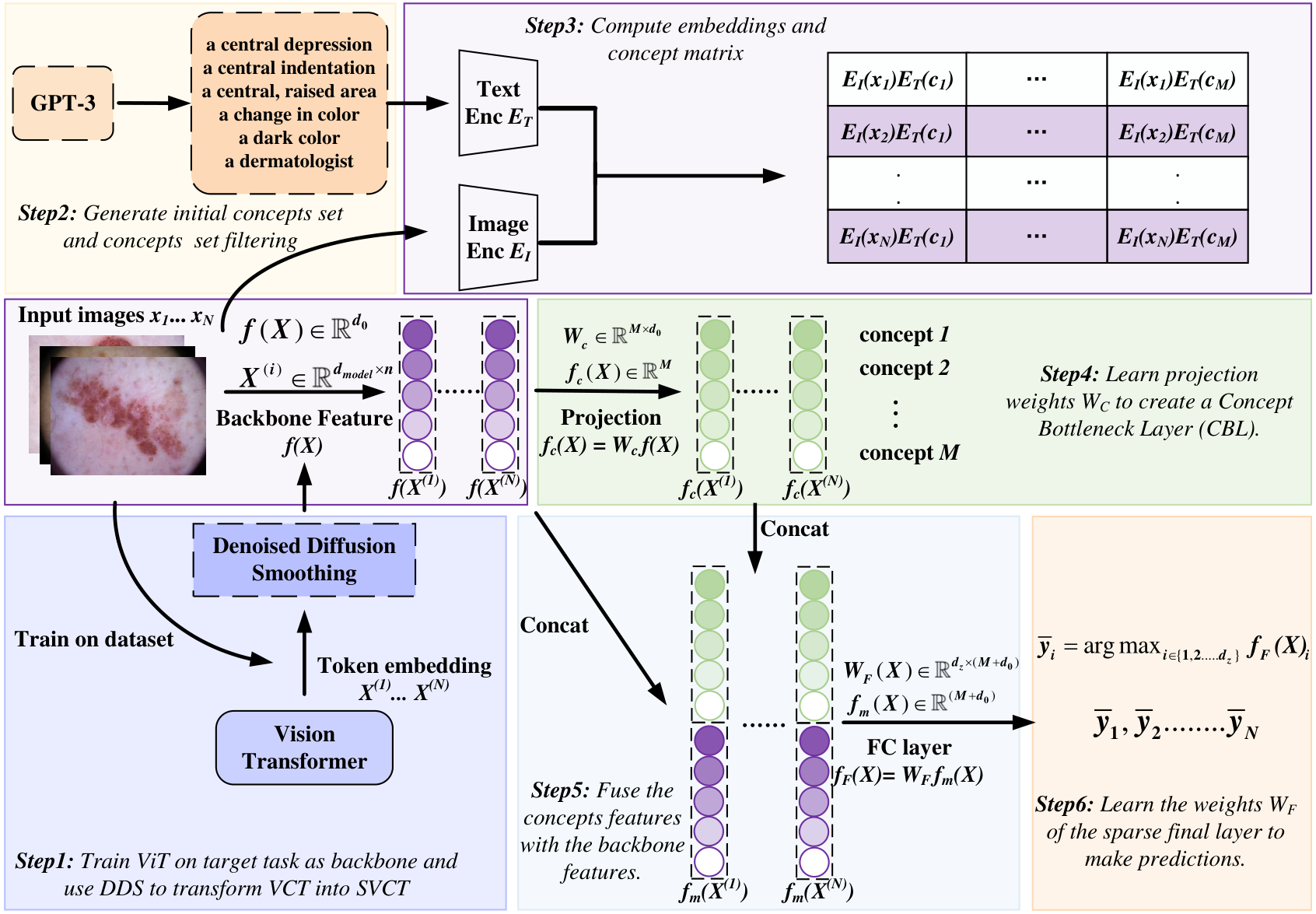
Stable Vision Concept Transformer (SVCT) 模型概览。
方法:VCT 与 SVCT
VCT (Vision Concept Transformer)
- ViT 骨干网络加上以 label-free 方式学习的 Concept Bottleneck Layer(例如 CLIP-Dissect)。
- 概念特征 f_c(X) 与骨干网络特征融合:F(X) = concat(f(X), W_c f(X)),用于最终分类器,避免仅依赖概念的 CBM 出现准确率下降。
SVCT (Stable VCT)
- 应用 Denoised Diffusion Smoothing:向 token embeddings 加入高斯噪声,再用 diffusion model 去噪。
- 得到稳定概念模块:(i) 解释稳定性:扰动下 top-k concept overlap ≥ β;(ii) 预测鲁棒性:预测间 Rényi divergence 有界。
- 默认噪声水平 σ = 8/255;评估使用扰动半径 ρ_u ∈ [6/255, 10/255]。
实验(来自论文)
数据集: HAM10000, Covid19-CT, BloodMNIST, OCT2017。扰动: PGD radius ρ_u ∈ [6/255, 10/255];DDS noise σ = 8/255。
准确率(有/无扰动)
| 方法 | HAM10000 | Covid19-CT | BloodMNIST | OCT2017 |
|---|---|---|---|---|
| Standard(无可解释性) | 99.13% | 81.62% | 97.05% | 99.70% |
| Label-Free CBM | 93.61% | 79.75% | 94.97% | 97.50% |
| Post-hoc CBM | 97.60% | 76.26% | 94.83% | 98.60% |
| VCT | 99.00% | 80.62% | 96.21% | 99.10% |
| SVCT | 99.05% | 81.37% | 96.96% | 99.50% |
| ρ_u=8/255 − LF-CBM | 90.08% | 67.98% | 80.53% | 91.88% |
| ρ_u=8/255 − SVCT | 97.97% | 74.45% | 94.07% | 98.70% |
| ρ_u=10/255 − LF-CBM | 88.70% | 65.12% | 75.63% | 90.58% |
| ρ_u=10/255 − SVCT | 97.24% | 71.65% | 92.65% | 98.48% |
稳定性:CFS 与 CPCS
CFS ↓(越低越好),CPCS ↑(越高越好)。SVCT 的稳定性始终最优。
| 方法 | HAM10000 (CFS/CPCS) | Covid19-CT (CFS/CPCS) | BloodMNIST (CFS/CPCS) | OCT2017 (CFS/CPCS) |
|---|---|---|---|---|
| ρ_u=6/255 − LF-CBM | 0.3335 / 0.9405 | 0.6022 / 0.8117 | 0.5328 / 0.8511 | 0.3798 / 0.9254 |
| ρ_u=6/255 − SVCT | 0.1354 / 0.9900 | 0.5555 / 0.8359 | 0.3589 / 0.9320 | 0.3257 / 0.9468 |
| ρ_u=8/255 − LF-CBM | 0.3719 / 0.9256 | 0.6707 / 0.7710 | 0.6280 / 0.7947 | 0.3941 / 0.9196 |
| ρ_u=8/255 − SVCT | 0.1555 / 0.9867 | 0.6446 / 0.7818 | 0.4383 / 0.8977 | 0.3459 / 0.9387 |
| ρ_u=10/255 − LF-CBM | 0.4027 / 0.9123 | 0.7224 / 0.7336 | 0.6906 / 0.7545 | 0.4055 / 0.9145 |
| ρ_u=10/255 − SVCT | 0.1725 / 0.9836 | 0.7096 / 0.7389 | 0.5058 / 0.8625 | 0.3620 / 0.9321 |
敏感性与特异性
| 方法 | HAM10000 (Sen/Spec) | Covid19-CT (Sen/Spec) | BloodMNIST (Sen/Spec) | OCT2017 (Sen/Spec) |
|---|---|---|---|---|
| Label-free CBM | 0.8878 / 0.9827 | 0.7984 / 0.8608 | 0.9407 / 0.9956 | 0.9750 / 0.9960 |
| SVCT | 0.9899 / 0.9999 | 0.8191 / 0.8037 | 0.9667 / 0.9958 | 0.9950 / 0.9994 |
| ρ_u=10/255 − LF CBM | 0.6779 / 0.9615 | 0.5794 / 0.9810 | 0.5880 / 0.9998 | 0.8380 / 0.9880 |
| ρ_u=10/255 − SVCT | 0.9180 / 0.9932 | 0.7136 / 0.9303 | 0.8681 / 0.9948 | 0.9790 / 0.9923 |
消融(DDS)
去噪(Denoising) 与 平滑(smoothing) 都很关键。二者同时启用时准确率与稳定性最佳(最低 CFS、最高 CPCS)。完整消融表见论文。
模型配置与计算成本
配置(论文表 4): batch_size 512, saga_batch_size 256, proj_batch_size 5000, clip_cutoff 0.25, proj_steps 1000, interpretability_cutoff 0.45, lam 0.0007, n_iters 1000, ρ_u ∈ [6/255, 10/255], S = 8/255.
成本: ViT 85.8M 参数 / 17.56 GFLOPS;Label-free CBM 85.76M (+40K);SVCT 85.85M (+43K),GFLOPS 相同。
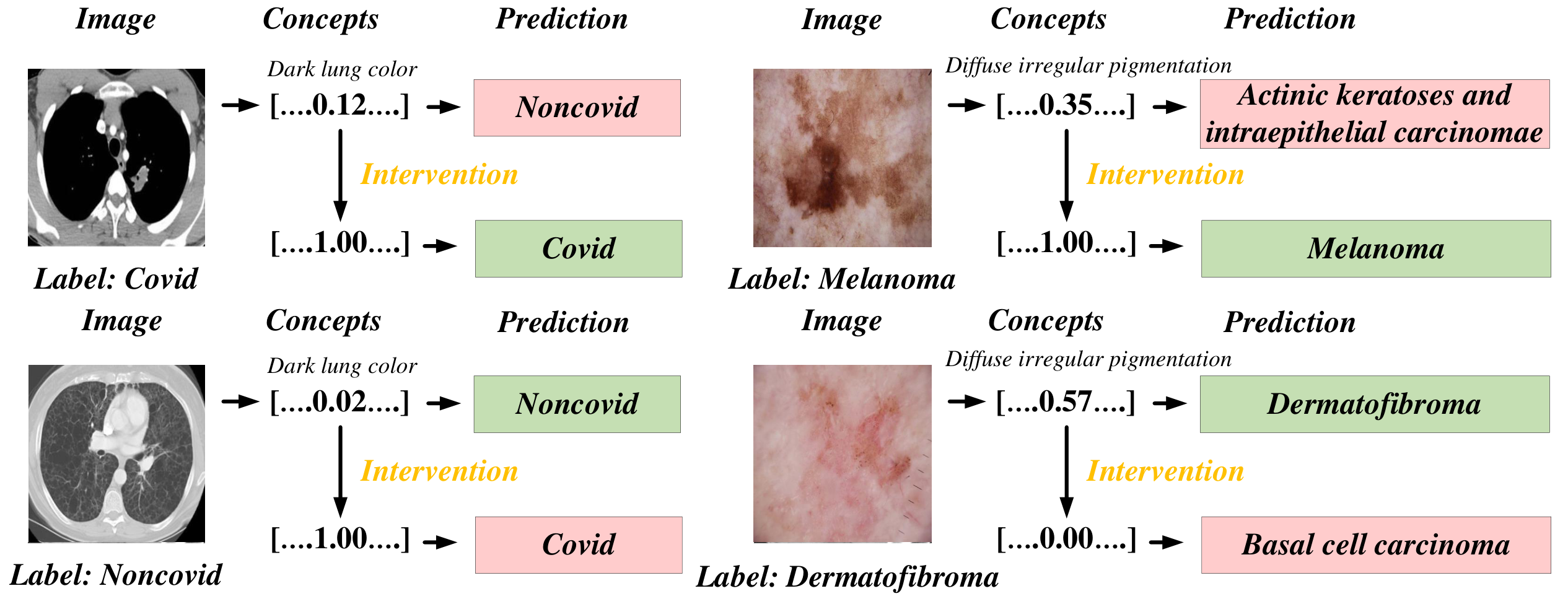
可视化
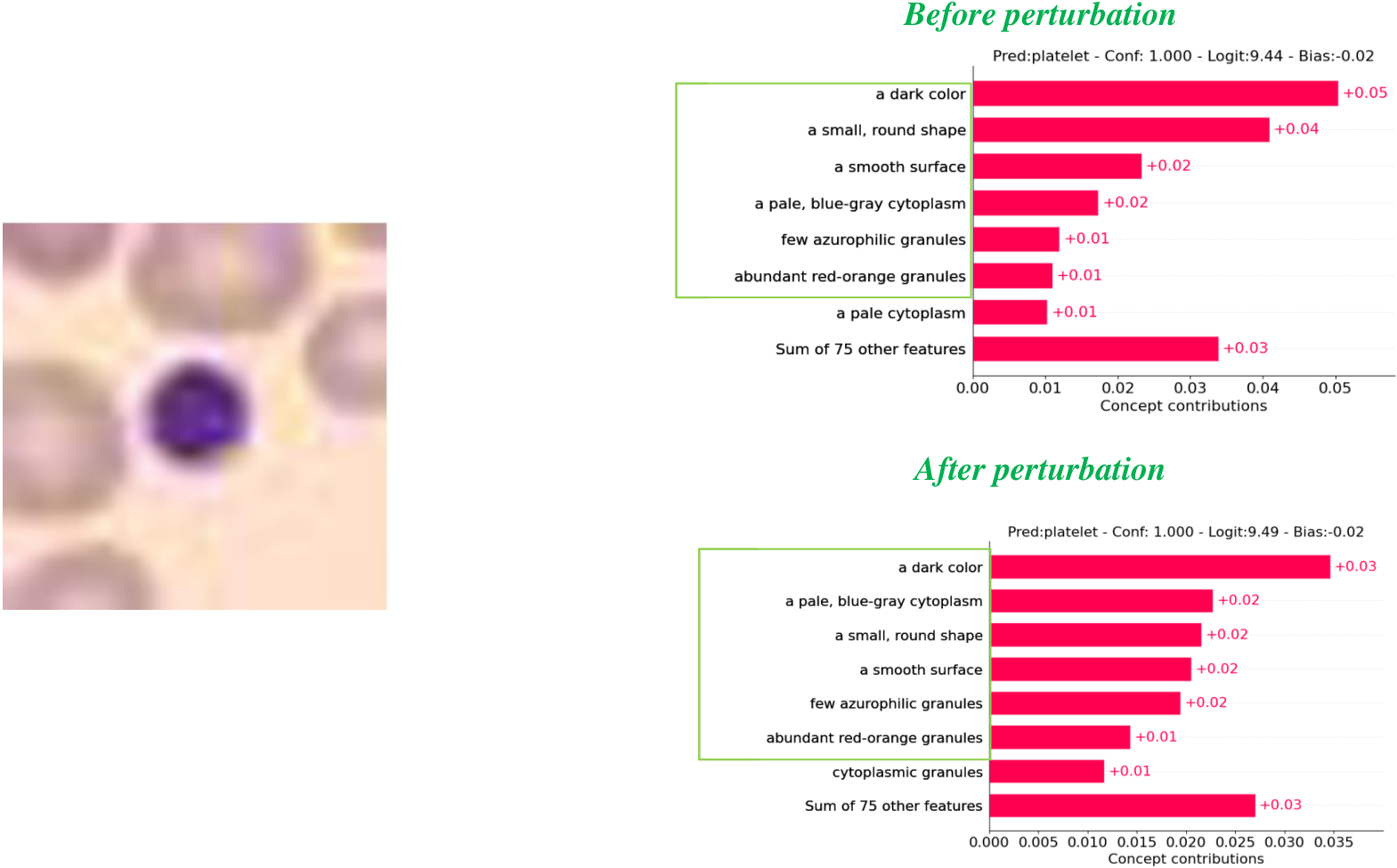
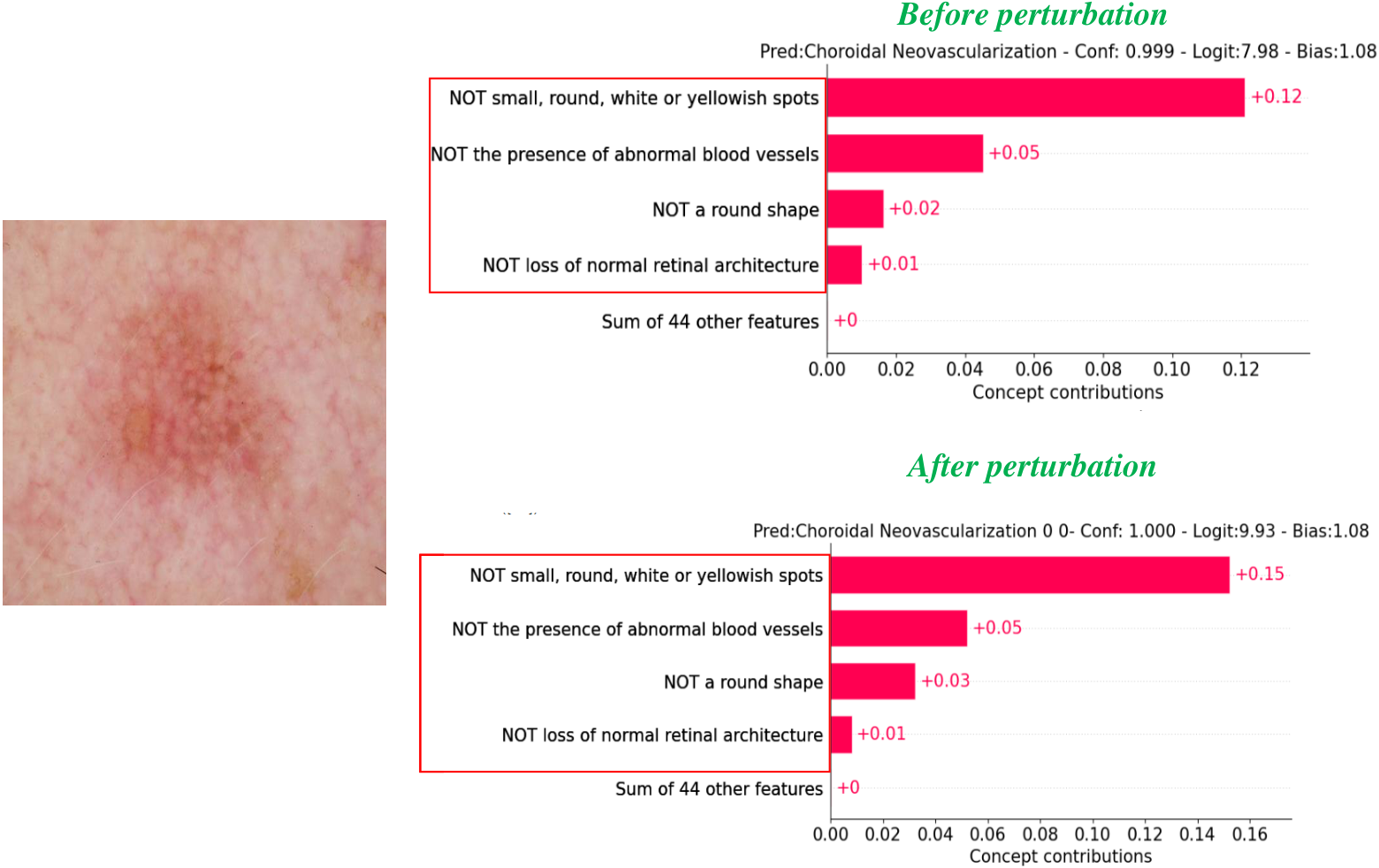
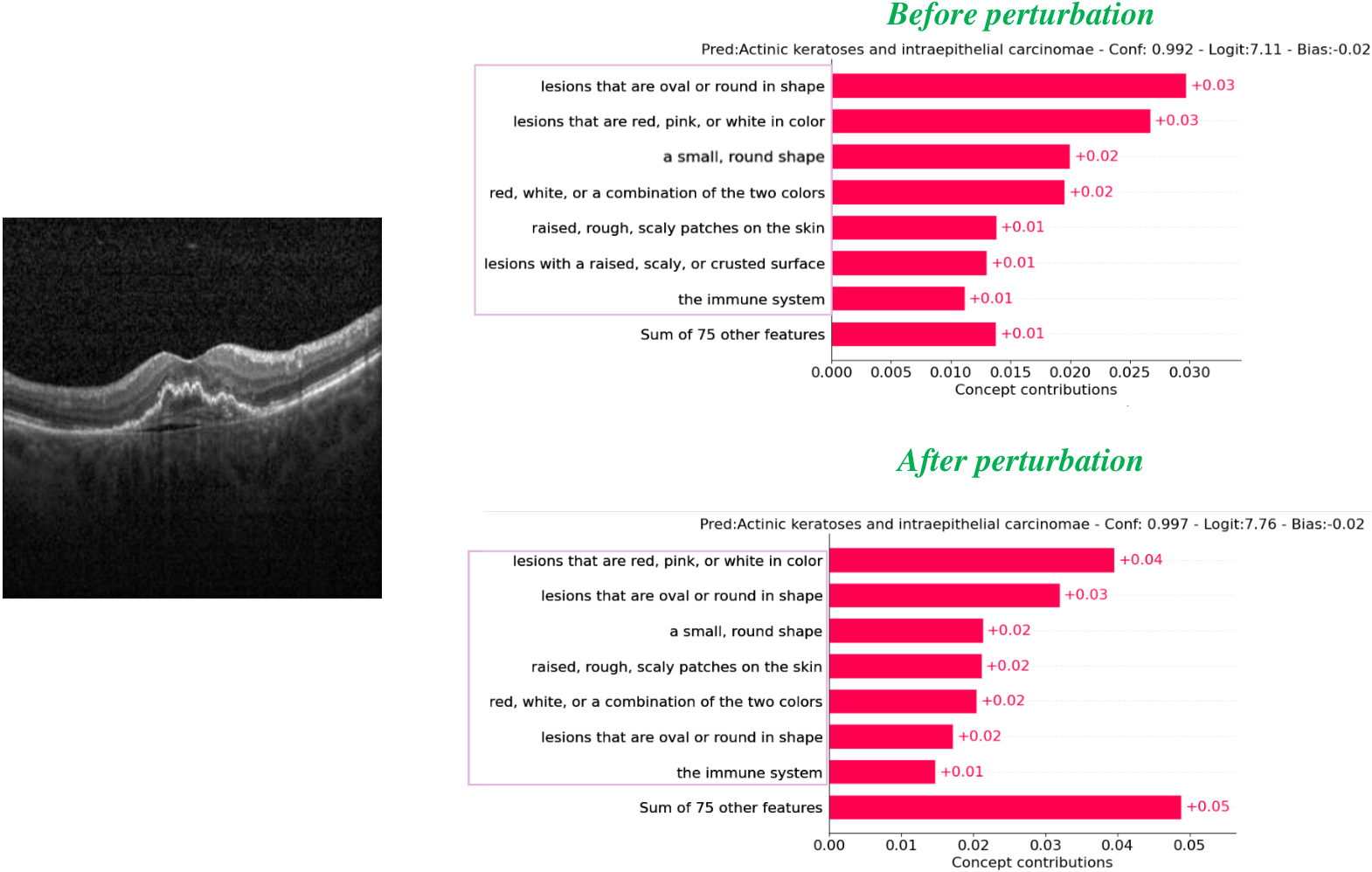
图 3:概念可视化 — 每个数据集一个样本,扰动前后对比。
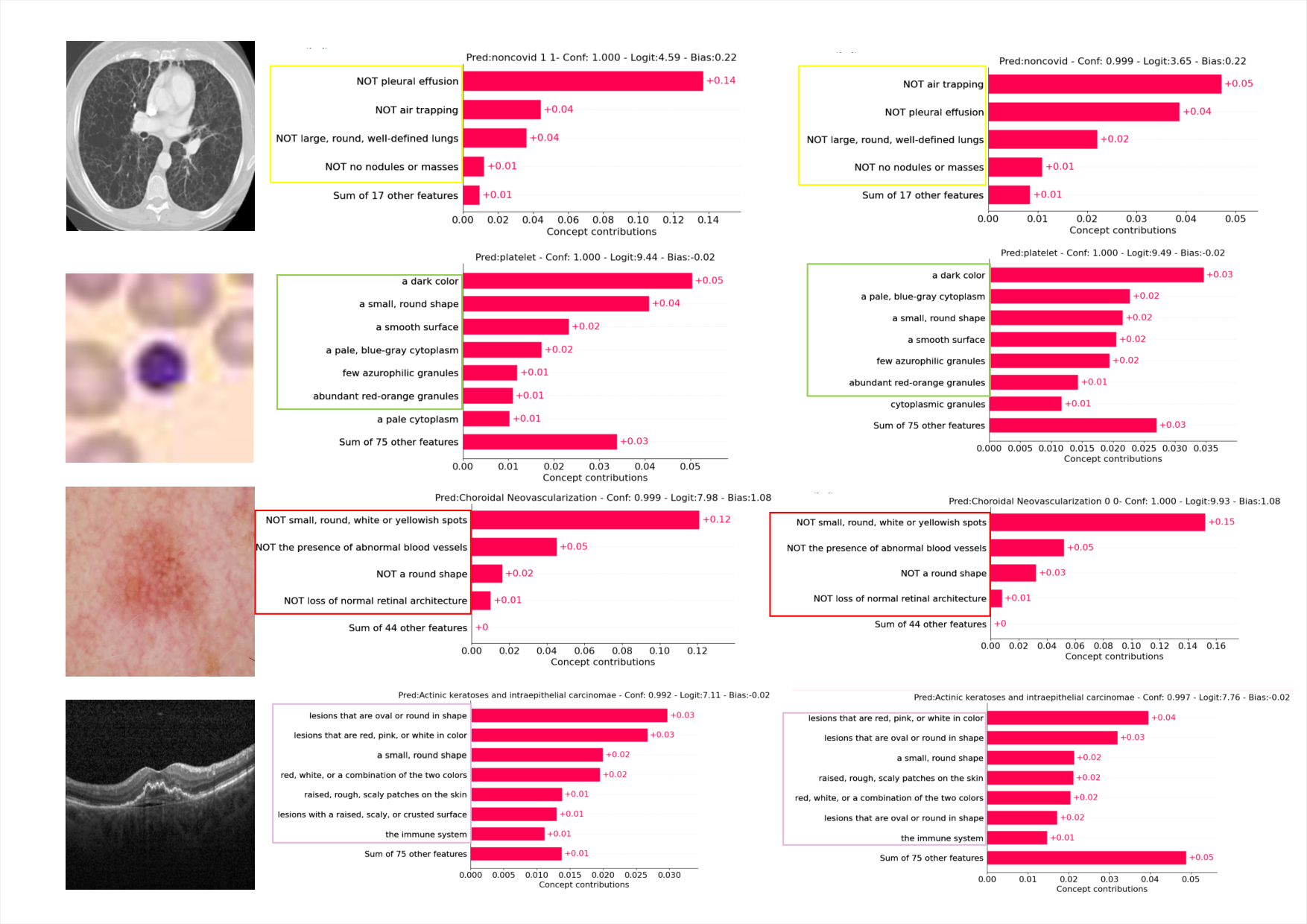
图 4:概念干预示例 — 专家可修正概念预测以辅助诊断。
各数据集概念权重可视化(Covid19-CT, BloodMNIST, HAM10000, OCT2017 各一个样本)。
代码与仓库
- GitHub(代码、notebooks、数据): github.com/xll0328/-ECML-2025-SVCT
- 论文 PDF: arXiv:2506.05286
引用
@inproceedings{hu2025stable,
title = {Stable Vision Concept Transformers for Medical Diagnosis},
author = {Hu, Lijie and Lai, Songning and Hua, Yuan and Yang, Shu and Zhang, Jingfeng and Wang, Di},
booktitle = {Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD)},
year = {2025}
}