ICLR 2024 · CCF A
FVLC: Faithful Vision-Language Interpretation via Concept Bottleneck Models
中文项目页
TL;DR
FVLC 对忠实的 label-free CBM 进行形式化定义和优化,在几乎不损失效用的情况下显著提升扰动下的概念与预测稳定性。
作者: Songning Lai, Lijie Hu, Junxiao Wang, Laure Berti-Equille, Di Wang
摘要
医疗和金融等领域对透明度的需求推动了可解释机器学习模型的发展,其中 Concept Bottleneck Models (CBMs) 因兼具性能潜力与深度神经网络洞察而受到重视。然而,CBM 对人工标注数据的依赖带来挑战。Label-free CBMs 被提出用于缓解这一问题,但它们仍然不稳定,影响其作为解释工具的忠实性。
我们提出 Faithful Vision-Language Concept (FVLC) 的形式化定义,并给出构造满足四个关键性质的 FVLC 方法。我们在 CIFAR-10、CIFAR-100、CUB 和 Places365 四个基准上实验,证明 FVLC 在输入扰动与概念集扰动(WP1、WP2、IP)下比基线更稳定,同时相比原始 Label-free CBM 仅有极小准确率损失。
动机:扰动下的不稳定性
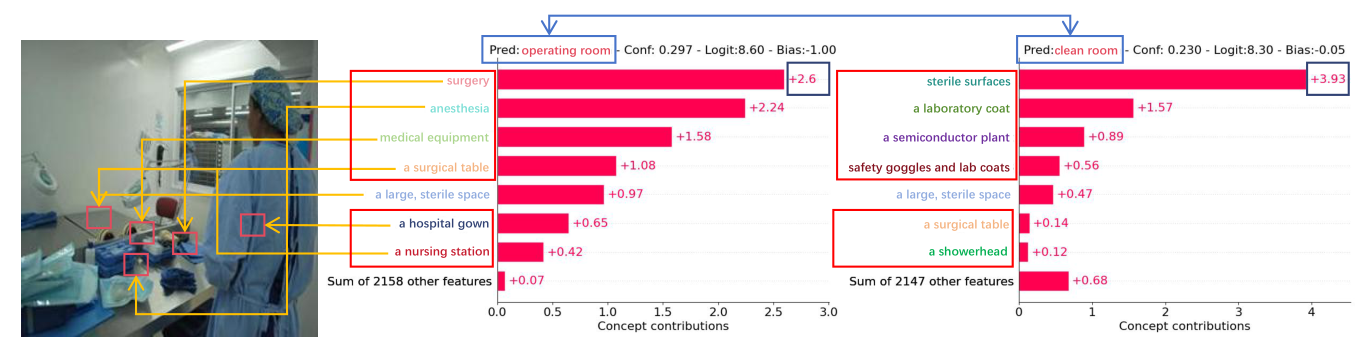
Places365 示例。最左侧为输入图像,相邻图为无扰动时的概念输出;右侧图展示施加概念词与输入扰动后的概念输出,概念位置和权重排名发生明显变化(例如 “surgery”),预测也在轻微扰动下发生改变。
流程概览
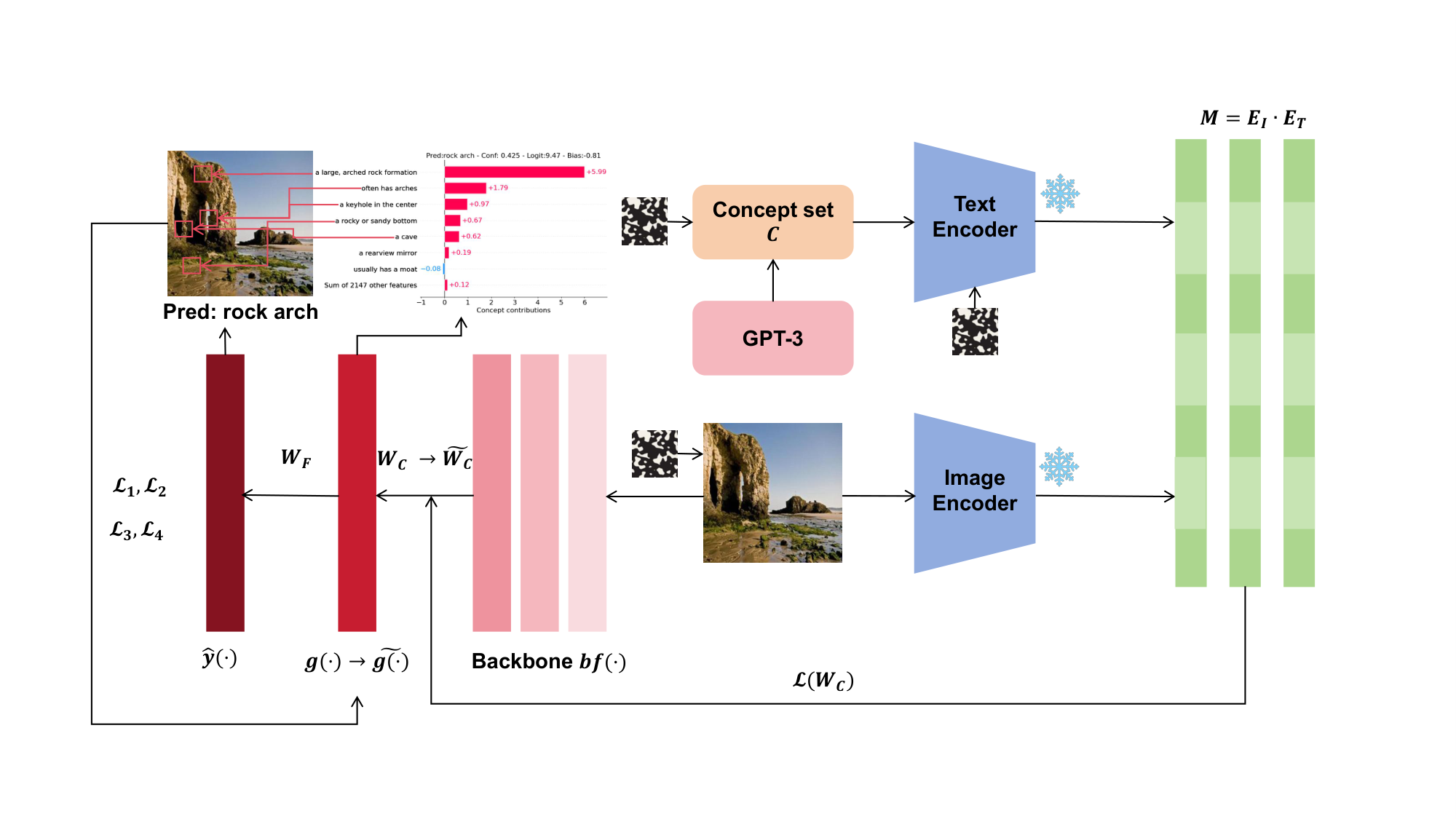
GPT-3 输出概念集 (\mathcal{C}),输入 CLIP 文本编码器得到 (E_T)。输入图像经 CLIP 图像编码器得到 (E_I),并经骨干网络提取图像特征。由 (E_I) 与 (E_T) 得到的激活矩阵 (M) 用于学习从特征空间到概念空间的映射 (g(\cdot)) 与 (W_c),再学习从概念空间到图像类别的映射 (W_F)。随后使用 (\mathcal{L}_1)/(\mathcal{L}_2)/(\mathcal{L}_3)/(\mathcal{L}_4) 增强模型忠实性((W_c \rightarrow \tilde{W}_c), (g(x) \rightarrow \tilde{g}(x)))。我们在概念集、文本编码器和输入图像中引入噪声,以验证模型忠实性。
Step 1:概念集创建

Step 1 示例:通过 GPT-3 创建概念集。
理论与方法
Top-$k$ overlap
对向量 (x \in \mathbb{R}^d),top-(k) 分量集合为:
\[T_k(x) = \bigl\{ i \in [d] : \bigl| \{ j : x_j \geq x_i \} \bigr| \leq k \bigr\}.\]两个向量 (x)、(x’) 的 top-(k) overlap 为:
\[V_k(x, x') = \frac{1}{k} \bigl| T_k(x) \cap T_k(x') \bigr|.\]Faithful Vision-Language Concept(Definition 1)
在相同概念空间下(一次由 GPT-3 生成的概念集合),如果对任意输入 (x),矩阵 (\tilde{W}_c) 满足下列性质,则称其为 vanilla concept 的 ((D, R, \alpha, \beta, k_1, k_2))-Faithful Vision-Language Concept (FVLC):
- 解释相似性: (V_{k_1}(\tilde{g}(x), g(x)) \geq \beta_1)。
- 解释稳定性: 对所有 (|\rho| \leq R_1),有 (V_{k_2}(\tilde{g}(x), \tilde{g}(x)+\rho) \geq \beta_2)。
- 预测接近性: (D(y(x, \tilde{c}), y(x, c)) \leq \alpha_1),其中 (D) 为概率距离(如 KL divergence)。
- 预测稳定性: 对所有 (|\delta| \leq R_2),有 (D(y(x, \tilde{c}), y(x, \tilde{c}+\delta)) \leq \alpha_2)。
其中 (\tilde{g}(x) = \tilde{W}_c \, \text{bf}(x))、(y(x, c) = W_F g(x))、(y(x, \tilde{c}) = W_F \tilde{g}(x))。
Min-max objective(Equation 7)
我们冻结图像编码器并求解 min-max 问题。总体目标为:
\[\min_{\tilde{W}_c} \mathbb{E}_x\Bigl[ \lambda_1 \underbrace{D(y(x, \tilde{c}), y(x, c))}_{\mathcal{L}_1} + \lambda_2 \underbrace{\mathcal{L}_{k_1}(\tilde{g}(x), g(x))}_{\mathcal{L}_2} + \lambda_3 \underbrace{\max_{\|\delta\| \leq R_2} D(y(x, \tilde{c}), y(x, \tilde{c}+\delta))}_{\mathcal{L}_3} + \lambda_4 \underbrace{\max_{\|\rho\| \leq R_1} \mathcal{L}_{k_2}(\tilde{g}(x), \tilde{g}(x)+\rho)}_{\mathcal{L}_4} \Bigr],\]其中 (\mathcal{L}_k) 是 (-V_k(\cdot, \cdot)) 的可微 surrogate,(D) 为 KL divergence。内部关于 (\delta) 与 (\rho) 的最大化使用 PGD,外部关于 (\tilde{W}_c) 的最小化使用梯度下降。
扰动与指标
- WP1 (Word Perturbation 1): 用同义词替换 5% 或 10% 的概念词(通过 GPT-3)。
- WP2 (Word Perturbation 2): 向文本嵌入加入高斯噪声 (\mathcal{N}(0, \sigma)),(\sigma = 0.001)。
- IP (Input Perturbation): 向归一化输入图像加入半径 (\sigma = 0.001) 的扰动。
TCPC(Total Concept Perturbation Change):(\texttt{TCPC}(c_1, c_2) = | c_1 - c_2 | / | c_1 |),衡量概念权重稳定性。
TOPC(Total Output Perturbation Change):(\texttt{TOPC}(y_1, y_2) = | y_1 - y_2 | / | y_1 |),衡量预测稳定性。
数值越低表示越稳定。
主要结果
表 1:准确率(%)
| 方法 | CIFAR10 | CIFAR100 | CUB | Places365 |
|---|---|---|---|---|
| Standard(无可解释性) | 88.80 | 70.10 | 76.70 | 48.56 |
| P-CBM (CLIP) | 84.50 | 56.00 | N/A | N/A |
| Label-free CBM | 86.32 | 65.42 | 74.23 | 43.63 |
| WP1(10%) – base | 86.25 | 65.09 | 73.97 | 43.67 |
| WP1(10%) – FVLC | 86.39 | 64.90 | 73.92 | 43.62 |
| WP2 – base | 86.41 | 65.16 | 73.96 | 43.54 |
| WP2 – FVLC | 86.22 | 65.34 | 74.44 | 44.55 |
| IP – base | 86.62 | 65.36 | 74.39 | 43.64 |
| IP – FVLC | 86.88 | 65.29 | 74.01 | 43.71 |
表 2:稳定性(TCPC / TOPC)— 越低越好
| 方法 | CIFAR10 | CIFAR100 | CUB | Places365 |
|---|---|---|---|---|
| WP1(10%) – base | 1.99E-01 / 8.36E-02 | 1.94E-01 / 1.31E-01 | 2.32E-01 / 3.41E-01 | 2.26E-01 / 1.14E-01 |
| WP1(10%) – FVLC | 1.19E-03 / 7.40E-03 | 3.67E-03 / 4.55E-03 | 1.19E-02 / 1.53E-03 | 1.39E-03 / 1.25E-03 |
| WP2 – base | 1.53E-01 / 4.99E-02 | 1.36E-01 / 6.67E-02 | 1.43E-01 / 1.73E-01 | 1.40E-01 / 6.37E-02 |
| WP2 – FVLC | 1.10E-02 / 8.72E-03 | 3.35E-03 / 4.55E-03 | 1.05E-02 / 1.53E-03 | 1.55E-03 / 1.29E-03 |
| IP – base | 1.68E-01 / 6.28E-02 | 1.38E-01 / 8.81E-02 | 1.71E-01 / 2.23E-01 | 1.73E-01 / 8.09E-02 |
| IP – FVLC | 8.02E-03 / 8.29E-03 | 3.24E-03 / 4.56E-03 | 1.04E-02 / 1.59E-03 | 1.50E-03 / 1.25E-03 |
消融(表 3)
对 (\mathcal{L}_2)、(\mathcal{L}_3)、(\mathcal{L}_4) 的消融显示三者均有贡献;全部使用(✓✓✓)可获得最佳 TCPC/TOPC。
可视化:概念权重与最后一层权重
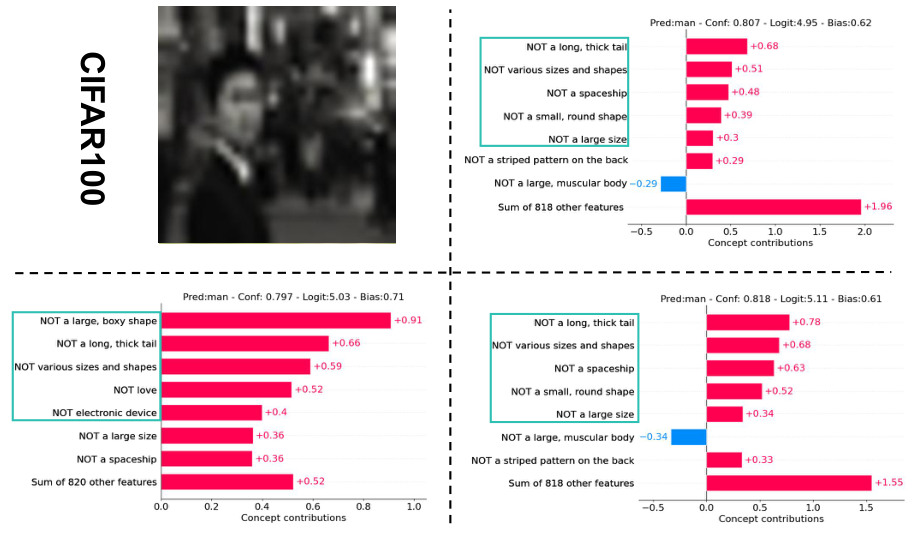
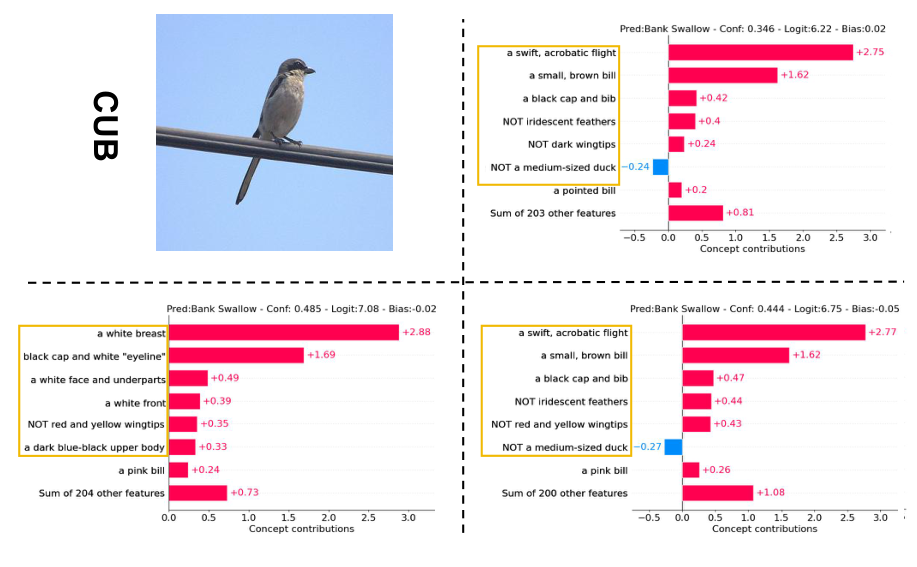
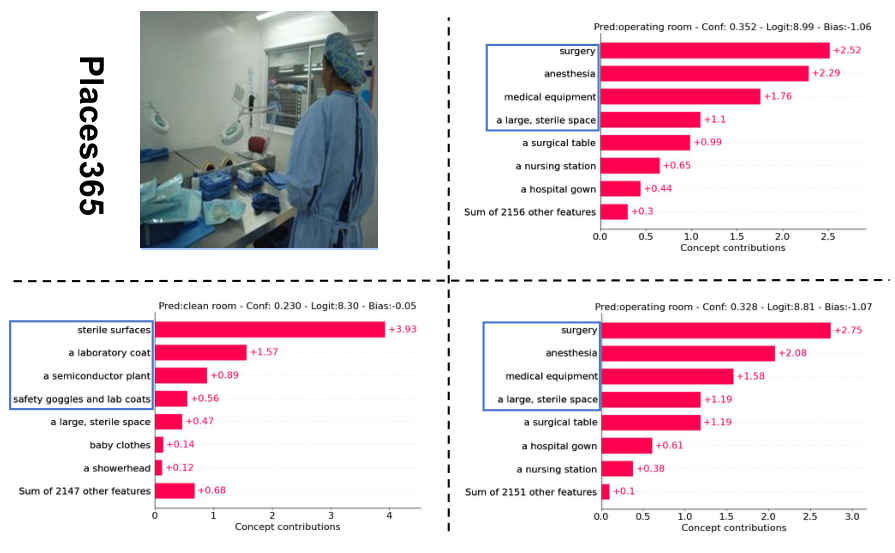
每个数据集一个样本(概览)
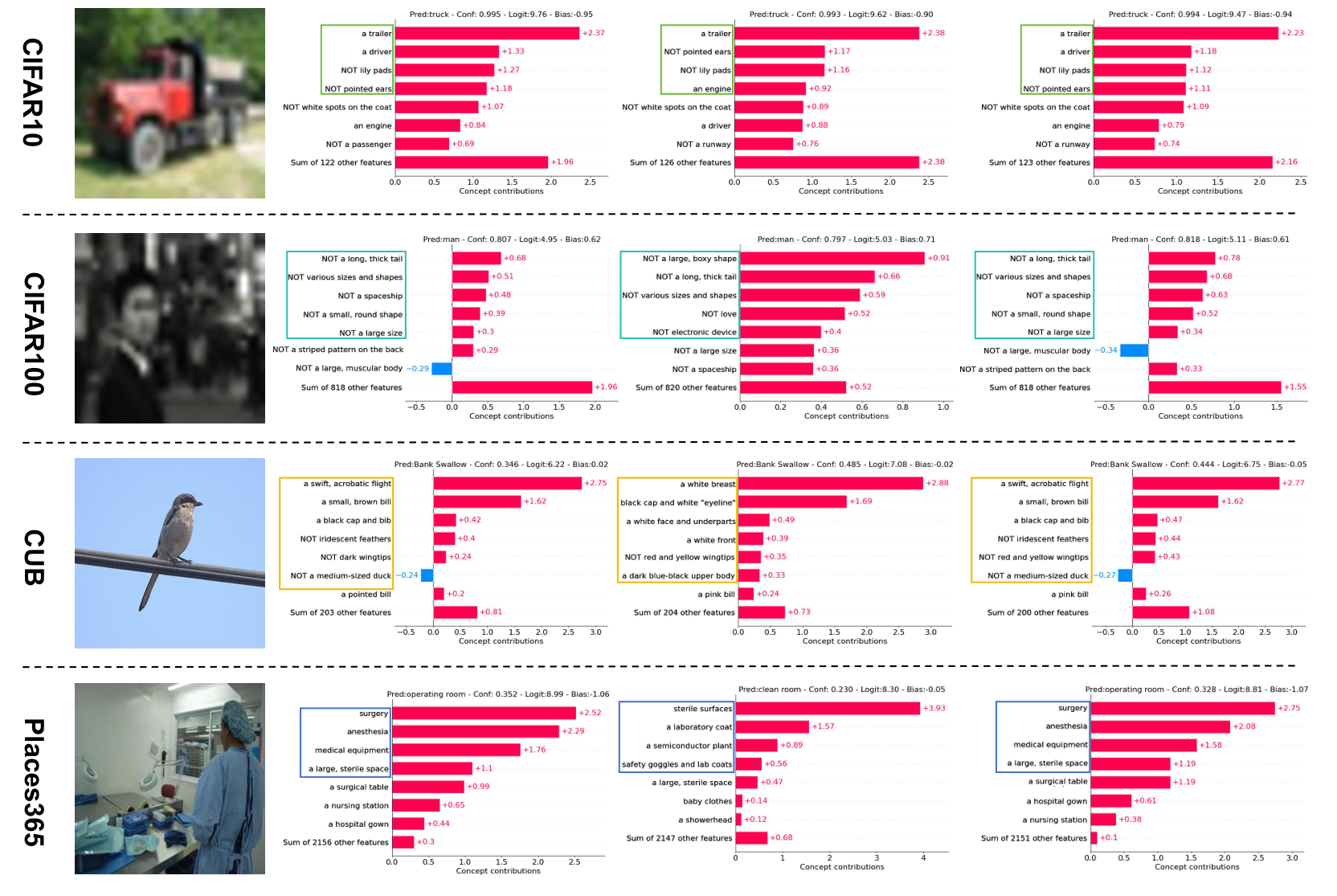
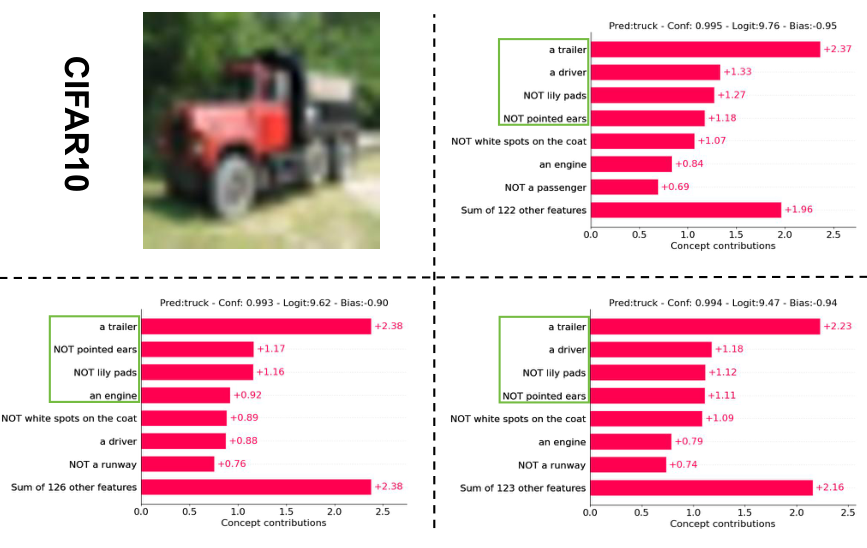
每个数据集一个样本的概念权重和最后一层权重可视化。从左到右分别为输入图像 (x)、无扰动的概念权重 (c)、扰动后的概念权重 (c+\delta),以及优化后带扰动的概念权重 (\tilde{c}+\delta)。
CIFAR-10
CIFAR-100
CUB
Places365
HAM10000(附录)
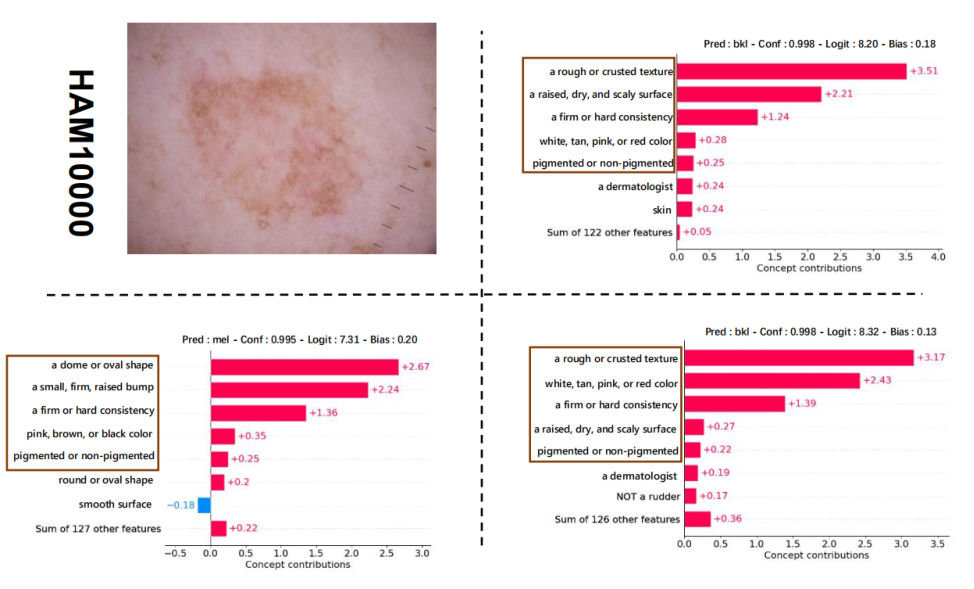
同一布局:输入图像、无扰动概念、带扰动概念、优化后带扰动概念。
代码与数据
- 仓库: https://github.com/xll0328/FVLC
- 数据集: CIFAR-10, CIFAR-100, CUB-200-2011, Places365(概念集位于
data/concept_sets/)。 - 训练:
train_cbm.py(base Label-free CBM)、train_fcbm_all.py(完整 FVLC)、train_fcbm_projonly.py(projection-only FVLC)。环境和命令见仓库 README。
引用
@inproceedings{lai2023faithful,
title={Faithful Vision-Language Interpretation via Concept Bottleneck Models},
author={Lai, Songning and Hu, Lijie and Wang, Junxiao and Berti-Equille, Laure and Wang, Di},
booktitle={The Twelfth International Conference on Learning Representations (ICLR)},
year={2024}
}