ICLR 2026 · CCF A · Core A*
ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
中文项目页
TL;DR
ACE 使用神经元级归因定位并编辑多跳事实回忆中的关键 query-value 路径,在 GPT-J 和 Qwen3-8B 上显著提升知识编辑有效性。
作者: Jiayu Yang†, Yuxuan Fan†, Songning Lai†, Shengen Wu, Jiaqi Tang, Chun Kang, Zhijiang Guo, Yutao Yue
框架(来自论文)
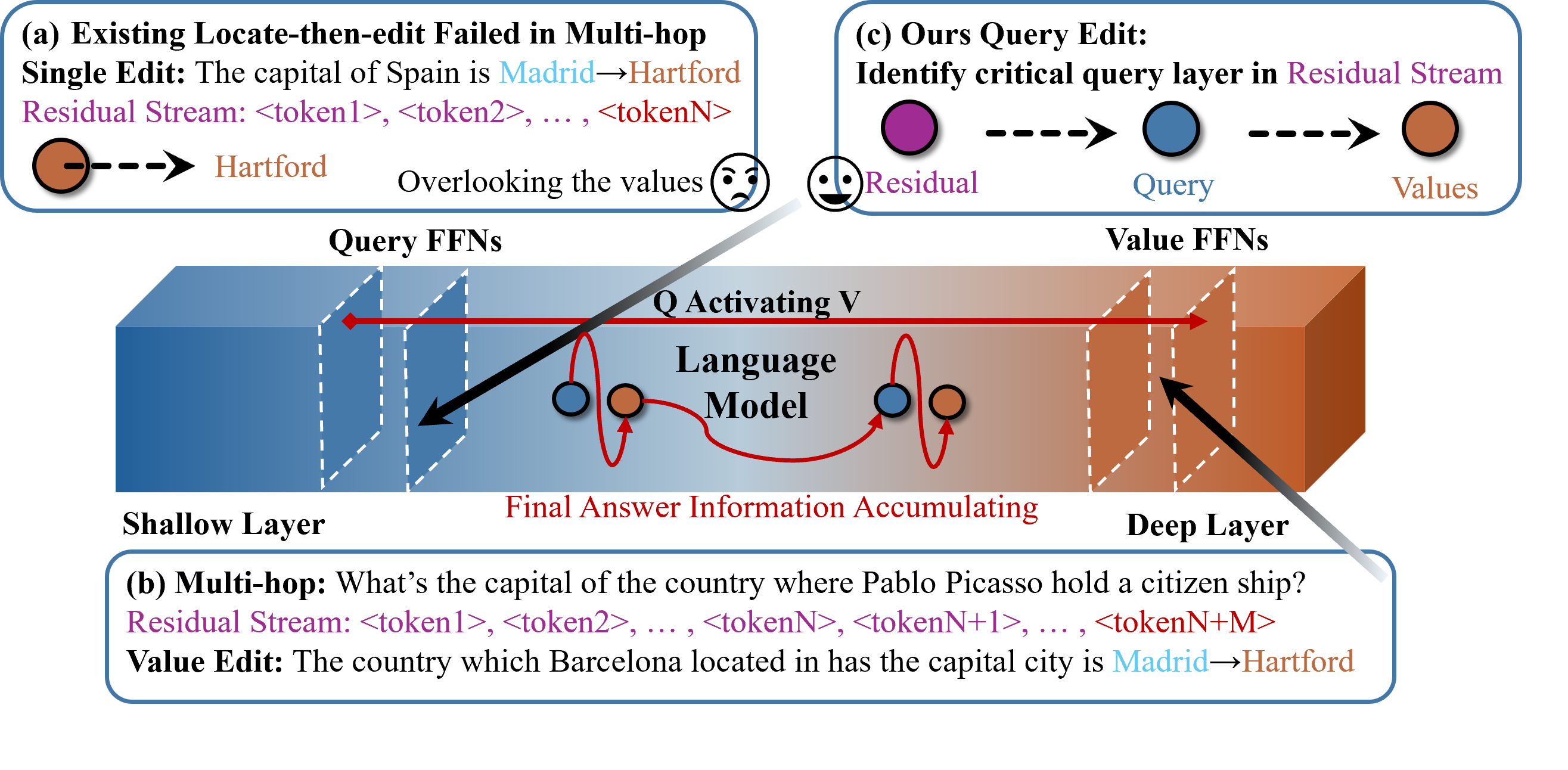
ACE 通过归因编辑 Q-V 神经元。 (a) 现有 locate-then-edit 知识编辑方法用单跳 prompt 更新新事实。(b) 面向多跳事实回忆时,传统 locate-then-edit 无法修正 query layers,也忽略 value neurons。(c) ACE 识别会激活 value neurons 的关键 query layers,并同时编辑两者。
多跳示例
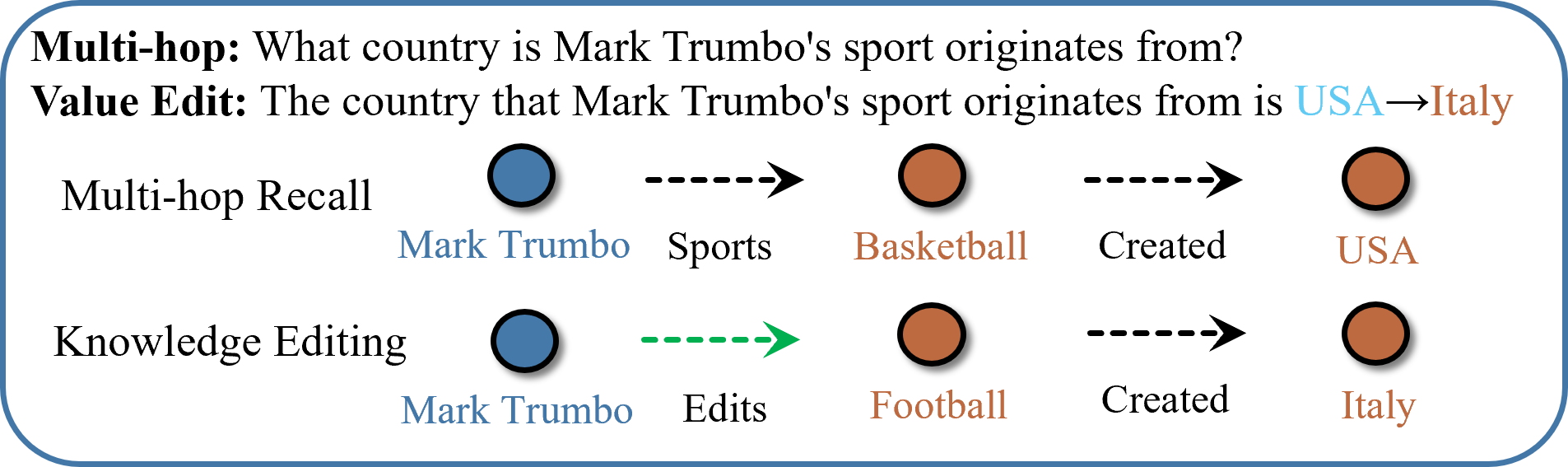
多跳事实回忆。 一个多跳查询会经过多个事实(例如 Mark Trumbo → Basketball → USA)。知识编辑(绿色)可以作用于中间事实;随后推理链会沿更新路径进行(Mark Trumbo → Football → Italy)。中间实体 “Football” 是隐式主体。
摘要
大语言模型需要高效知识编辑(KE)来更新事实信息,但现有方法在多跳事实回忆中表现明显衰退。当编辑涉及推理链中的中间隐式主体时,这一问题尤其严重。通过因果分析,我们发现该限制源于现有方法忽略了链式知识如何在神经元层面动态表示和使用。我们发现,在多跳推理中,隐式主体作为 “query neurons” 工作,顺序激活 Transformer 层中的对应 “value neurons”,从而向最终答案累积信息。我们提出 ACE(Attribution-Controlled Knowledge Editing),利用神经元级归因识别并编辑关键 query-value(Q-V)路径。ACE 在 GPT-J 上比 SOTA 高 9.44%,在 Qwen3-8B 上高 37.46%。
主要贡献
- 机制:在多跳事实回忆中,隐式主体作为 query neurons 顺序激活 value neurons;LLM 将语义相关知识存储在结构相似组件中,并具有一致的 Q-V 定位。
- ACE:通过神经元级归因识别关键 query 与 value layers;基于 PMET 骨干模型顺序编辑二者(中浅层 FFN 中的 query layers 与深层 FFN 中的 value layers)。
- 结果:相较 SOTA,在 GPT-J 上 +9.44%,在 Qwen3-8B 上 +37.46%;消融显示跳过 top query layers 会造成约 16.51% 下降,跳过 value layers 会造成约 40.45% 下降。
预备知识(符号)
第 (l) 层 hidden state:
\[h_i^l = h_i^{l-1} + A_i^l + F_i^l,\]其中 (A_i^l) 为 attention output,(F_i^l) 为 FFN output。FFN output 是神经元的加权和:
\[F_i^l = \sum_{k=1}^N m_{i,k}^l \cdot fc2^l_k, \qquad m_{i,k}^l = \sigma(fc1_k^l \cdot (h^{l-1}_i + A^l_i)).\]Value neurons 的重要性得分(log probability increase):
\[\mathcal{I}(v^l) = \log p(w \mid v^l + h^{l-1}) - \log p(w \mid h^{l-1}), \qquad \mathcal{I}(l) = \sum_{v \in l} \mathcal{I}(v^l).\]Query neurons 的重要性得分:
\[\mathcal{I}_{\mathrm{query}} = v \cdot fc1^l_k, \qquad \mathcal{I}_{\mathrm{query}}(l) = \sum_{v \in l} \mathcal{I}(v^l).\]ACE 流程
- 阶段 1:识别。 使用 (\mathcal{I}) 和 (\mathcal{I}_{\mathrm{query}}) 对 query 与 value layers 排序,选择 top layers 进行编辑。
- 阶段 2:定位并编辑。 对识别出的 value layers 和 query-related layers 进行 FFN value matrices 编辑(PMET-style),使更新后的知识在多跳推理中沿 Q-V 路径被激活。
主要结果
多跳准确率(MQuAKE-3K subset, few-shot)
Avg. 表示 GPT-J 与 Qwen3-8B 的平均值。# Edits 表示链中被编辑事实数量(1-4)。第 3-6 列为 GPT-J,第 7-10 列为 Qwen3-8B。
| Editor | Avg. (GPT / Qwen) | GJ 1-edit | GJ 2-edit | GJ 3-edit | GJ 4-edit | Qw 1-edit | Qw 2-edit | Qw 3-edit | Qw 4-edit |
|---|---|---|---|---|---|---|---|---|---|
| Base | 98.42 / 99.17 | 99.7 | 95.48 | 97.51 | 97.23 | 99.81 | 97.46 | 98.14 | 97.64 |
| FT | 3.54 / 2.18 | 4.17 | 2.63 | 0.00 | 0.00 | 3.14 | 2.79 | 0.00 | 0.00 |
| ROME | 35.04 / 28.79 | 44.51 | 38.93 | 17.52 | 5.06 | 35.09 | 32.48 | 18.97 | 7.08 |
| MEMIT | 38.58 / 18.67 | 64.30 | 16.87 | 17.25 | 8.16 | 29.84 | 19.18 | 12.91 | 4.20 |
| PMET | 37.01 / 20.78 | 49.26 | 36.30 | 24.34 | 17.01 | 28.64 | 14.08 | 12.56 | 11.20 |
| ACE | 46.45 / 58.24 | 45.26 | 50.24 | 36.17 | 43.29 | 60.22 | 59.48 | 51.62 | 47.61 |
详细指标(Efficacy / Paraphrase / Specificity)
| Editor | Efficacy (GPT-J / Qwen3) | Paraphrase | Specificity |
|---|---|---|---|
| FT | 98.4 / 97.1 | 74.5 / 73.2 | 83.8 / 79.6 |
| ROME | 64.2 / 51.8 | 61.6 / 49.3 | 66.8 / 57.2 |
| MEMIT | 62.8 / 53.6 | 66.2 / 61.8 | 70.0 / 64.7 |
| PMET | 81.6 / 75.6 | 65.8 / 68.9 | 74.6 / 64.4 |
| ACE | 99.8 / 99.4 | 91.2 / 94.2 | 79.2 / 81.8 |
消融(跳过层)
跳过 top query 或 value layers 会显著损害性能。“Editor” 表示被跳过的层;↓ 表示相对完整 ACE 的下降。
| Editor | Avg. (GPT-J-6B) | Avg. (Qwen3-8B) |
|---|---|---|
| Skip #1 query | 43.26 (↓6.87%) | 52.61 (↓9.67%) |
| Skip #1,2 query | 41.19 (↓11.32%) | 47.34 (↓18.71%) |
| Skip #1,2,3 query | 38.78 (↓16.51%) | 45.26 (↓22.29%) |
| Skip #1 value | 42.14 (↓9.28%) | 51.39 (↓11.76%) |
| Skip #1,2 value | 33.97 (↓26.87%) | 34.68 (↓40.45%) |
知识瓶颈(编辑层数量)
在相同编辑层数量(#N)下,ACE 仍保持明显优势;仅编辑 value 的方法存在知识瓶颈,增加编辑层数带来的收益有限。
| Editor | Avg. (GPT-J) | Editor | Avg. (Qwen3-8B) |
|---|---|---|---|
| #9 - ROME | 37.98 | #8 - ROME | 30.16 |
| #9 - MEMIT | 39.47 | #8 - MEMIT | 21.95 |
| #9 - PMET | 38.29 | #8 - PMET | 21.14 |
| #9 - ACE | 46.45 | #8 - ACE | 58.24 |
代码与引用
@inproceedings{yang2026ace,
title={ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall},
author={Yang, Jiayu and Fan, Yuxuan and Lai, Songning and Wu, Shengen and Tang, Jiaqi and Kang, Chun and Guo, Zhijiang and Yue, Yutao},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}