MICCAI 2026 · CCF B · Provisionally Accepted
SANT-CBM: Structurally-Aware and Noise-Tolerant Semi-supervised Concept Bottleneck Models
Project page
TL;DR
SANT-CBM improves semi-supervised Concept Bottleneck Models for dermatology diagnosis by down-weighting noisy pseudo-labels with GMM-based dynamic weighting and enforcing clinically plausible concept correlations through structural consistency.
Authors: HongWei Liu, Jia Liu, Songning Lai~
Venue: Medical Image Computing and Computer Assisted Intervention (MICCAI 2026, CCF B), provisionally accepted
Note: ~ denotes corresponding author. Paper and code links will be added after the applicable MICCAI public-release and artifact-release requirements are satisfied.
Overview
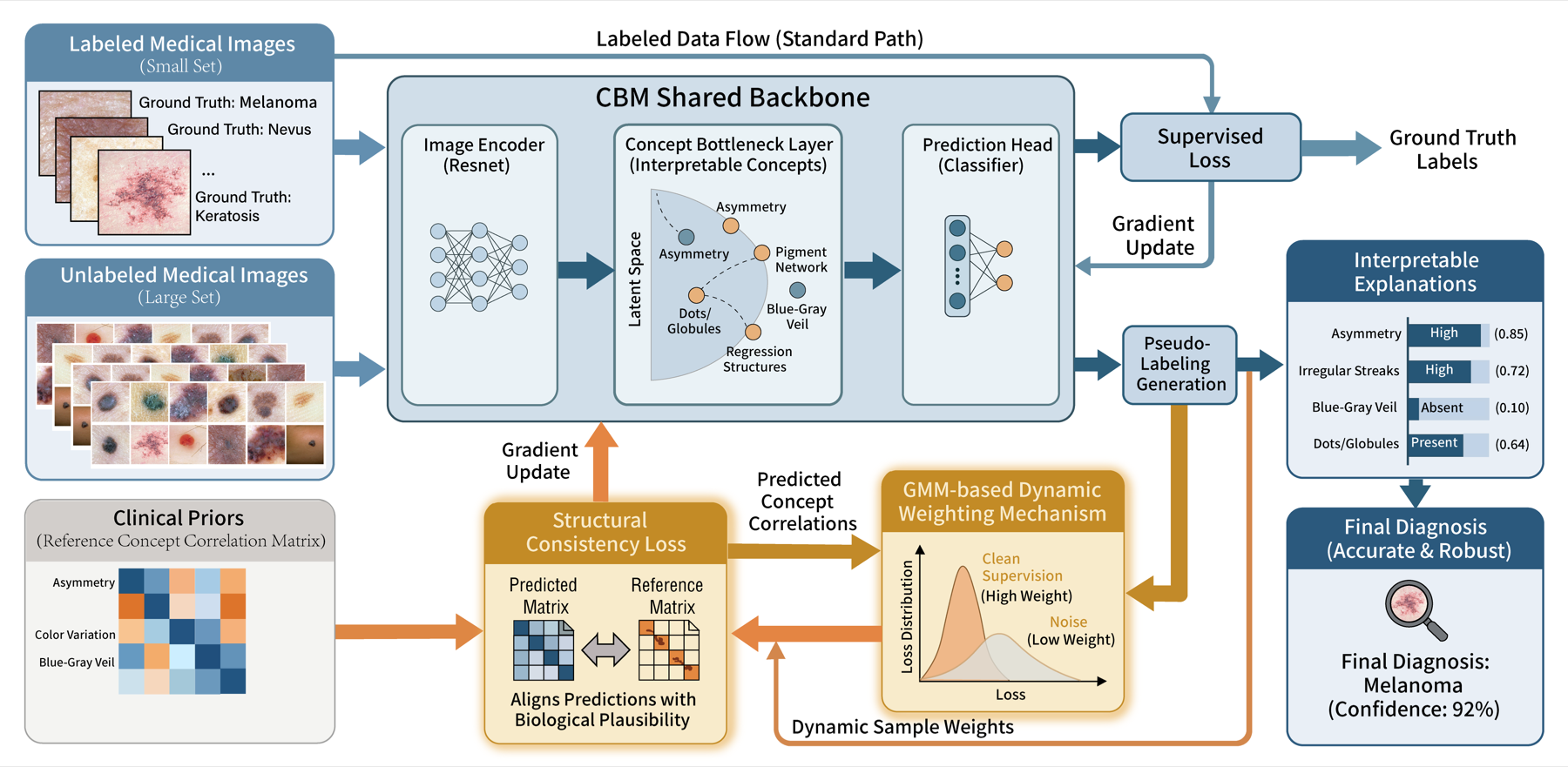
Concept Bottleneck Models (CBMs) make medical image classifiers more interpretable by predicting human-understandable clinical concepts before the final diagnosis. In label-scarce medical settings, however, semi-supervised CBMs face two reliability issues: noisy pseudo-labels from unlabeled data and concept predictions that may violate pathological correlations.
SANT-CBM addresses both issues with two complementary branches:
- Noise-Tolerant learning: a GMM-based dynamic weighting mechanism estimates whether each concept-level pseudo-label is clean or noisy from its loss distribution, then down-weights unreliable supervision.
- Structurally-Aware learning: a structural consistency loss aligns predicted concept correlations with a reference correlation matrix derived from clinical priors, encouraging biologically plausible concept combinations.
Method
The model follows a CBM pipeline with a concept predictor and a label predictor. For unlabeled samples, SANT-CBM generates initial pseudo concept labels from a feature bank, then uses a two-component Gaussian Mixture Model to estimate concept-wise cleanliness weights.
The denoised pseudo-label loss is:
\[\mathcal{L}_{denoise} = \frac{1}{N_U}\sum_{i=1}^{N_U}\sum_{j=1}^{M} w_{i,j}\cdot(g(\mathbf{u}_i)_j-\tilde{c}_{i,j})^2.\]For structural consistency, the model computes a differentiable batch-wise concept correlation matrix and aligns it to the clinical reference matrix:
\[\mathcal{L}_{struct} = \left\|\mathbf{R}_{ref}-\hat{\mathbf{R}}_{batch}\right\|_F^2.\]The full objective combines supervised CBM training, noise-tolerant pseudo-label alignment, and structural consistency:
\[\mathcal{L}_{total} = \mathcal{L}_{sup}+\lambda_u\mathcal{L}_{denoise}+\lambda_s\mathcal{L}_{struct}.\]
Results
SANT-CBM is evaluated on two public dermatology datasets: Fitzpatrick17k and 7-point Checklist. Under the 10% labeled setting, it improves task accuracy over the state-of-the-art semi-supervised CBM baseline.
| Dataset | SSCBM Task Acc. | SANT-CBM Task Acc. | Gain |
|---|---|---|---|
| Fitzpatrick17k | 71.52% | 77.83% | +6.31% |
| 7-point Checklist | 67.52% | 73.27% | +5.75% |
Ablation on Fitzpatrick17k
| GMM Denoising | Structural Loss | Concept Acc. | Task Acc. |
|---|---|---|---|
| - | - | 86.31% | 71.51% |
| Yes | - | 87.81% | 74.38% |
| - | Yes | 86.47% | 75.13% |
| Yes | Yes | 88.84% | 77.83% |
Visualization
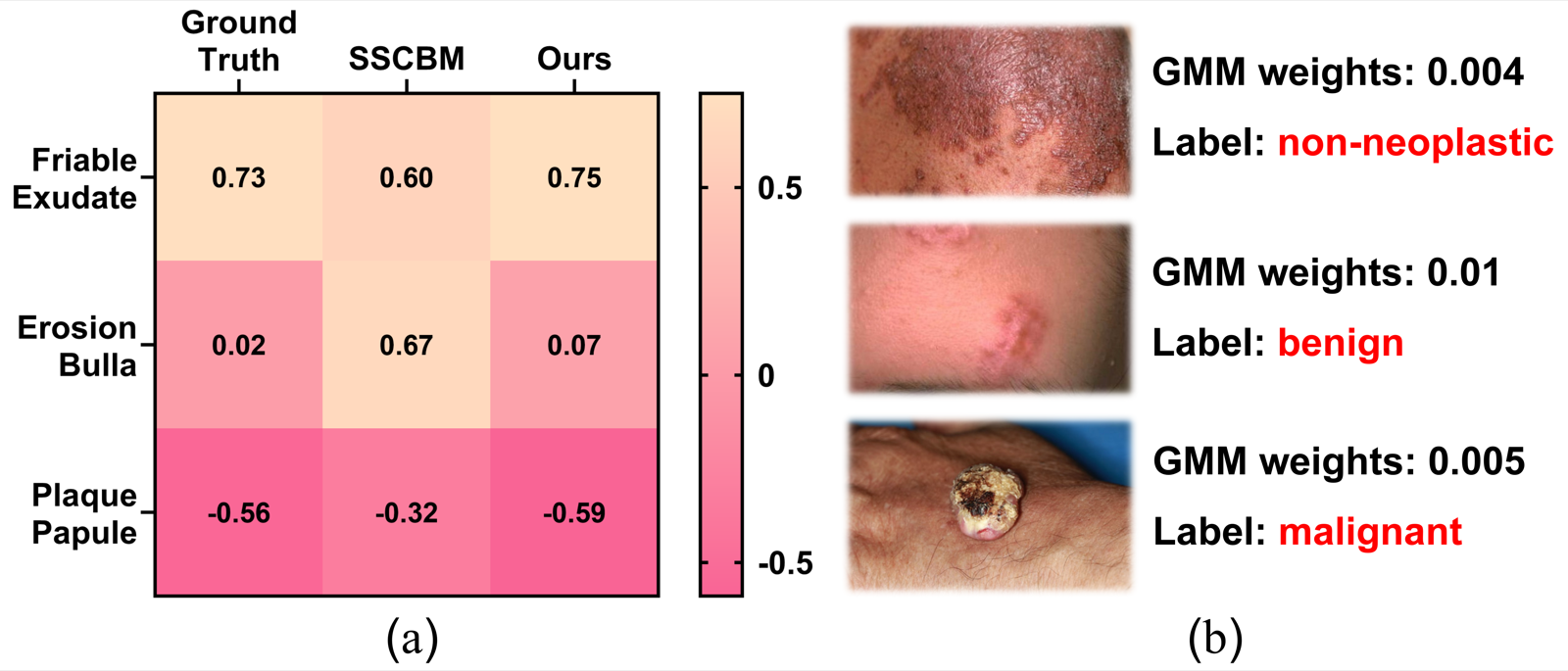
The qualitative analysis shows that SANT-CBM better matches the reference concept-correlation structure than SSCBM, while the GMM module identifies low-confidence unlabeled examples and reduces their influence during training.
Release
The paper is provisionally accepted to MICCAI 2026. Public paper links, citation metadata, and repository links will be updated after the camera-ready and MICCAI public-release process is finalized.