
NeurIPS 2024 · CCF A
Med-MICN: Towards Multi-dimensional Explanation Alignment for Medical Classification
Official project page
TL;DR
Med-MICN aligns concept semantics, neural-symbolic reasoning, and saliency explanations in one medical framework, delivering strong performance with multi-dimensional interpretability.
Authors: Lijie Hu†, Songning Lai†, Wenshuo Chen† (equal contribution), Hongru Xiao, Hongbin Lin, Lu Yu, Jingfeng Zhang, Di Wang
Abstract
The lack of interpretability in the field of medical image analysis has significant ethical and legal implications. Existing interpretable methods in this domain encounter several challenges, including dependency on specific models, difficulties in understanding and visualization, as well as issues related to efficiency. To address these limitations, we propose a novel framework called Med-MICN (Medical Multi-dimensional Interpretable Concept Network). Med-MICN provides interpretability alignment for various angles, including neural symbolic reasoning, concept semantics, and saliency maps, which are superior to current interpretable methods. Its advantages include high prediction accuracy, interpretability across multiple dimensions, and automation through an end-to-end concept labeling process that reduces the need for extensive human training effort when working with new datasets. We apply Med-MICN to four benchmark datasets and compare it with baselines; the results clearly demonstrate the superior performance and interpretability of our Med-MICN.
Framework overview
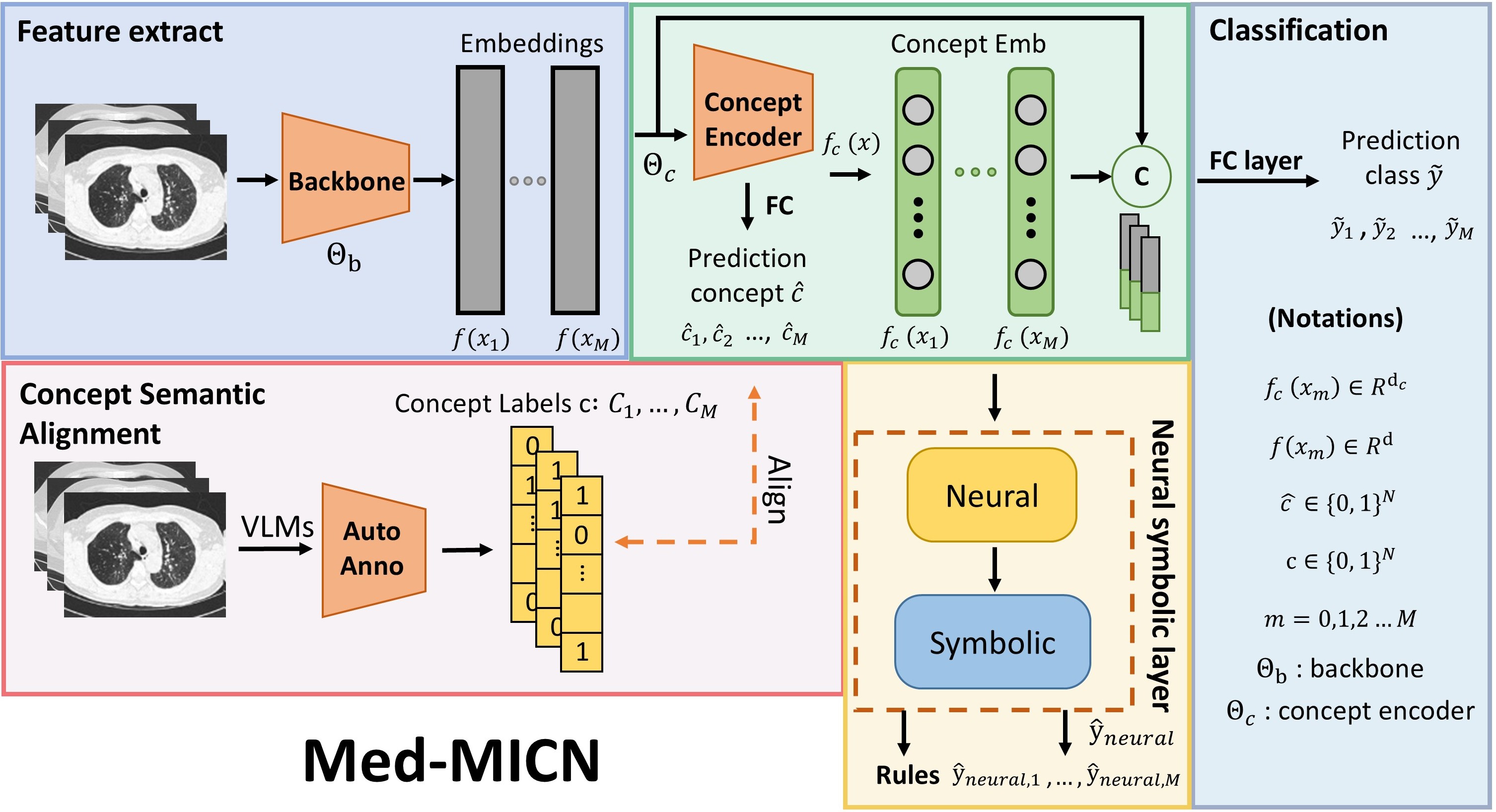
Overview of the Med-MICN framework. Four primary modules: (1) Feature Extraction Module — image features are extracted using a backbone network. (2) Concept Embedding Module — extracted features are fed into the concept embedding module to output concept embeddings and predicted category information. (3) Concept Semantic Alignment — a Vision-Language Model (VLM) is used to annotate image features and generate concept category annotations aligned with predicted categories. (4) Neural Symbolic Layer — concept embeddings are input into the neural symbolic layer to derive conceptual rules. Concept embeddings are concatenated with original image embeddings and fed into the final category prediction layer to produce the ultimate prediction results.
Multi-dimensional interpretability
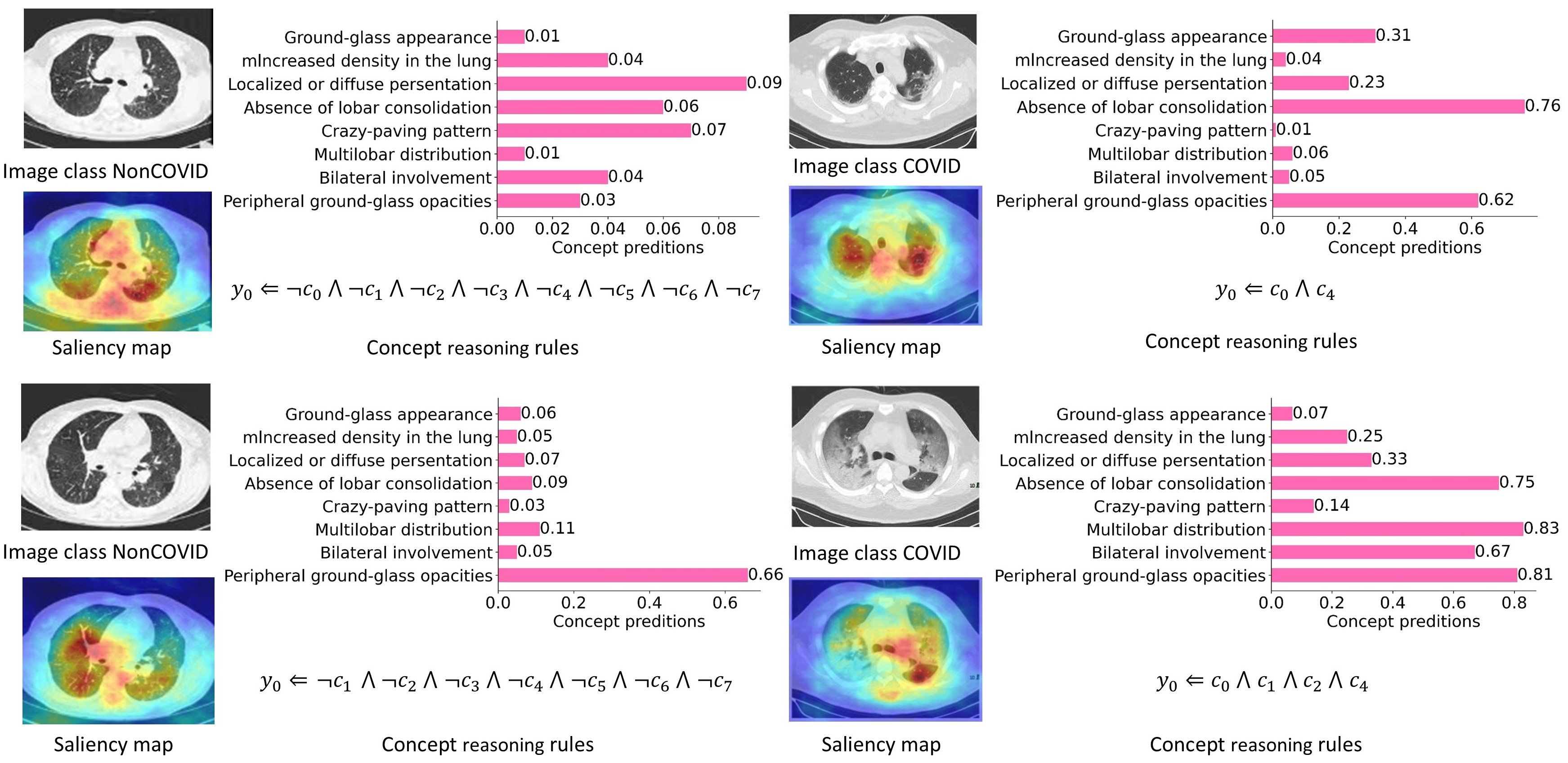
Med-MICN demonstrates multidimensional interpretability, encompassing concept score prediction, concept reasoning rules, and saliency maps, achieving alignment within the interpretative framework. Along the y-axis, concepts $c_0, \ldots, c_7$ are shown (e.g. “Peripheral ground-glass opacities” as $c_0$).
Concept labeling alignment
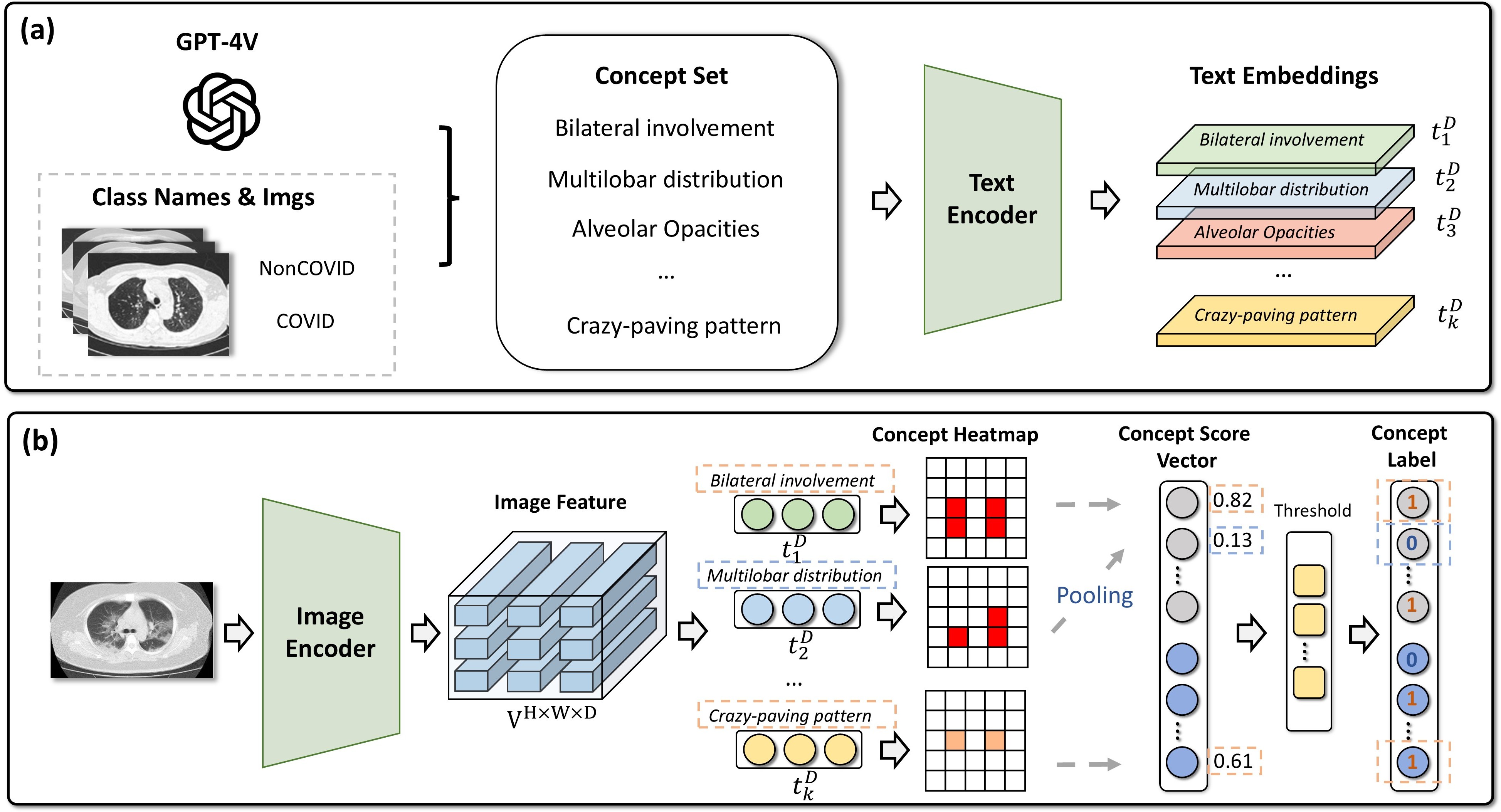
Automatic concept labeling alignment: (a) concept set generation (e.g. via GPT-4V); (b) VLM-based concept heatmaps and pseudo-labels aligned with the concept set.
Method (key formulas)
Heatmap and concept score. Given visual feature map $V$ and text embedding $t_i$ for concept $c_i$, the similarity heatmap is
\[P_{h,w,i} = \frac{t_i^T V_{h,w}}{\|t_i\| \cdot \|V_{h,w}\|}.\]Average pooling gives concept score $s_i = \frac{1}{H \cdot W} \sum_{h,w} P_{h,w,i}$; concept vector $e = (s_1, \ldots, s_N)^T$.
Concept embedding. Backbone $\Theta_b$ and concept encoder $\Theta_c$:
\[f(x_m) = \Theta_b(x_m), \quad f_c(x_m), \hat{C}_m = \Theta_c(f(x_m)).\]Concept loss:
\[\mathcal{L}_c = \mathrm{BCE}(\hat{c}, c).\]Neural-symbolic layer. For each class $j$, concept polarity $I_{o,i,j}$ and relevance $I_{r,i,j}$ are combined (fuzzy logic):
\[\hat{y}_j = \land_{i=1}^{N} ( \neg I_{o, i, j} \lor I_{r, i, j} ) = \min_{i \in [N]} \{ \max\{1-I_{o, i, j} , I_{r, i, j}\} \}.\]Final prediction and loss. Fused prediction $\tilde{y}_m = W_F \cdot \mathrm{Concat}(f(x_m), f_c(x_m))$. Overall loss:
\[\mathcal{L} = \mathcal{L}_{\mathrm{task}} + \lambda_1 \cdot \mathcal{L}_{c} + \lambda_2 \cdot \mathcal{L}_{\mathrm{neural}},\]where
\[\mathcal{L}_{\mathrm{task}} = \mathrm{CE}(\tilde{y}, y), \quad \mathcal{L}_{\mathrm{neural}} = \mathrm{BCE}(\hat{y}_{\mathrm{neural}}, y), \quad \lambda_1 = \lambda_2 = 0.1.\]Single- vs multi-dimensional interpretability
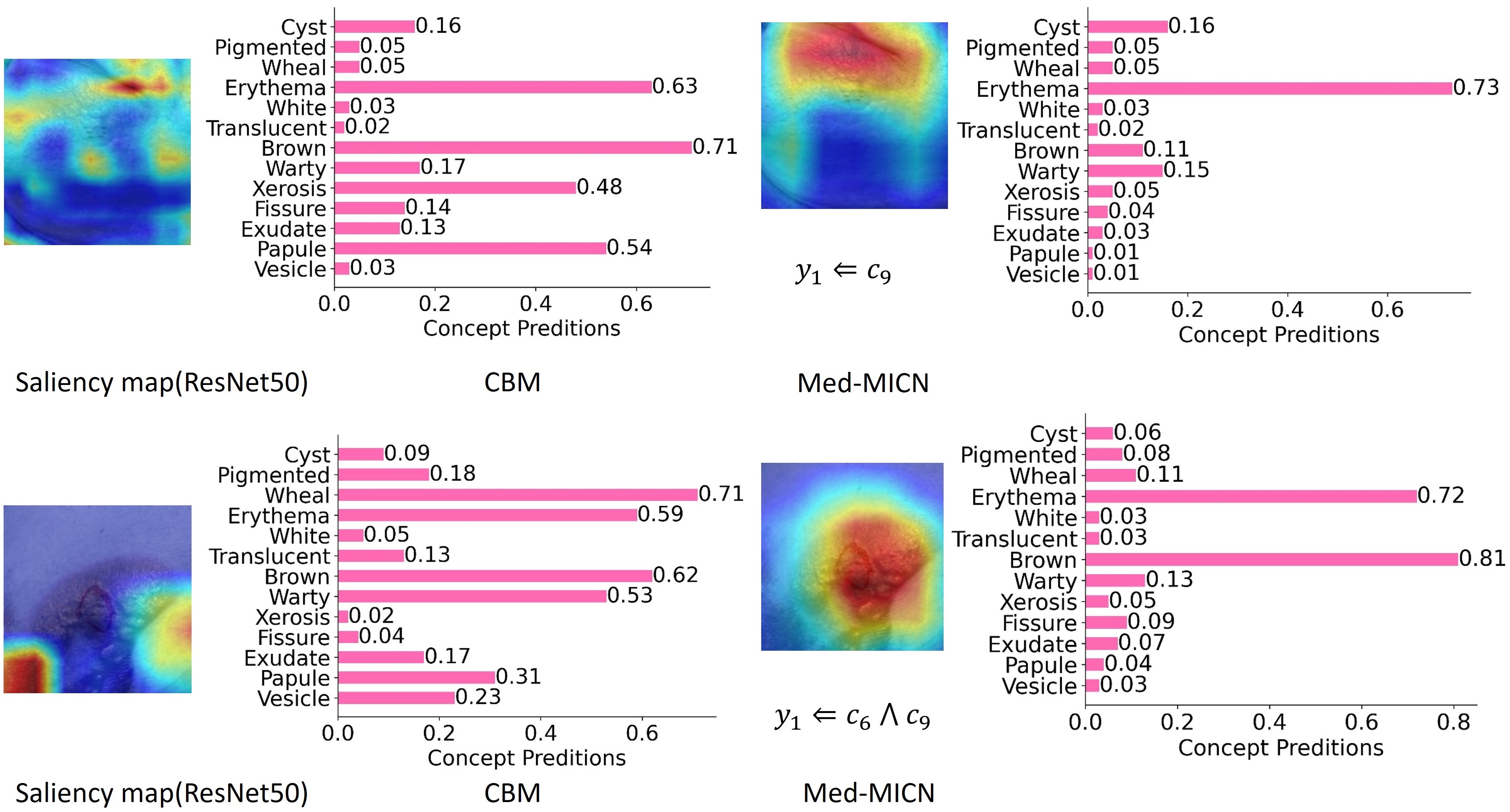
Comparison of single-dimensional and multi-dimensional interpretability methods. Relying solely on saliency maps or concept embeddings does not furnish adequate interpretability; by integrating multi-dimensional strategies, the model aligns information across dimensions and yields more comprehensive interpretable information and more correct predictions.
Main results
Utility results (Acc.% / F1%)
| Method | Backbone | COVID-CT | DDI | Chest X-Ray | Fitzpatrick17k | Interpretability |
|---|---|---|---|---|---|---|
| Baseline | ResNet50 | 81.36 / 81.67 | 77.27 / 72.77 | 75.64 / 71.72 | 80.79 / 80.79 | × |
| Baseline | VGG19 | 79.60 / 79.88 | 76.52 / 70.12 | 81.41 / 77.56 | 75.37 / 75.37 | × |
| Baseline | DenseNet169 | 85.59 / 85.59 | 78.03 / 69.51 | 69.55 / 61.66 | 76.85 / 76.83 | × |
| Label-free CBM | — | 69.49 / 69.21 | 70.34 / 69.21 | 71.21 / 70.84 | 75.24 / 75.41 | ✓ |
| DCR | — | 55.93 / 51.41 | 76.52 / 65.32 | 62.02 / 41.33 | 68.05 / 66.12 | ✓ |
| Ours | ResNet50 | 84.75 / 84.75 | 81.82 / 76.33 | 78.37 / 74.42 | 82.76 / 83.03 | ✓ |
| Ours | VGG19 | 83.05 / 84.37 | 82.58 / 78.07 | 88.30 / 88.16 | 77.34 / 77.53 | ✓ |
| Ours | DenseNet169 | 86.44 / 87.15 | 79.55 / 69.79 | 73.88 / 65.70 | 80.79 / 81.11 | ✓ |
Ablation study
Ablation (ResNet50): using both the concept loss and the neural loss yields the best Acc./AUC across COVID-CT, DDI, Chest X-Ray, and Fitzpatrick17k. For example on DDI, using only the concept loss gives +3.79% AUC; using only the neural loss does not notably improve; both together give +8.71% AUC.
Ablation table (Acc.% / Precision% / Recall% / F1% / AUC%). Checkmarks indicate the loss term is used.
| Dataset | Concept loss | Neural loss | ACC | Precision | Recall | F1 | AUC | Interpretability |
|---|---|---|---|---|---|---|---|---|
| COVID-CT | 82.20 | 82.92 | 82.21 | 82.55 | 82.64 | |||
| ✓ | 83.05 | 83.62 | 83.16 | 83.01 | 83.16 | |||
| ✓ | 81.36 | 82.11 | 81.38 | 81.70 | 81.81 | |||
| ✓ | ✓ | 84.75 | 84.77 | 84.88 | 84.75 | 84.77 | ✓ | |
| DDI | 78.03 | 74.97 | 66.88 | 69.24 | 67.41 | |||
| ✓ | 79.55 | 75.36 | 71.47 | 72.73 | 71.20 | |||
| ✓ | 78.79 | 76.38 | 66.29 | 68.69 | 67.64 | |||
| ✓ | ✓ | 81.82 | 76.56 | 76.17 | 76.33 | 76.12 | ✓ | |
| Chest X-Ray | 68.59 | 69.63 | 61.11 | 61.02 | 62.05 | |||
| ✓ | 72.28 | 77.63 | 64.15 | 63.72 | 64.15 | |||
| ✓ | 70.03 | 73.83 | 61.84 | 61.25 | 62.39 | |||
| ✓ | ✓ | 78.37 | 80.38 | 73.12 | 74.42 | 73.12 | ✓ | |
| Fitzpatrick17k | 78.33 | 79.50 | 78.32 | 78.91 | 79.06 | |||
| ✓ | 79.80 | 80.60 | 79.81 | 80.20 | 80.31 | |||
| ✓ | 80.79 | 81.28 | 80.82 | 81.28 | 81.07 | |||
| ✓ | ✓ | 82.76 | 82.84 | 83.23 | 83.03 | 82.99 | ✓ |
Datasets and usage
Datasets: COVID-CT (CT images), DDI (dermatology), Chest X-Ray, Fitzpatrick17k (dermatology with skin colors).
Code: https://github.com/xll0328/NeurIPS24-Med_MICN
# Training with different backbones
python train_skin_neural.py --backbone RN50
python train_skin_neural.py --backbone DenseNet
python train_skin_neural.py --backbone DINOv2
Citation
@inproceedings{hu2024medmicn,
title={Towards Multi-dimensional Explanation Alignment for Medical Classification},
author={Hu, Lijie and Lai, Songning and Chen, Wenshuo and Xiao, Hongru and Lin, Hongbin and Yu, Lu and Zhang, Jingfeng and Wang, Di},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2024}
}