
ICLR 2024 · CCF A
FVLC: Faithful Vision-Language Interpretation via Concept Bottleneck Models
Official project page
TL;DR
FVLC formalizes and optimizes faithful label-free CBMs, significantly improving concept/prediction stability under perturbations with minimal utility drop.
Authors: Songning Lai, Lijie Hu, Junxiao Wang, Laure Berti-Equille, Di Wang
Abstract
The demand for transparency in healthcare and finance has led to interpretable machine learning (IML) models, notably Concept Bottleneck Models (CBMs), valued for their potential in performance and insights into deep neural networks. However, CBM’s reliance on manually annotated data poses challenges. Label-free CBMs have emerged to address this, but they remain unstable, affecting their faithfulness as explanatory tools.
We introduce a formal definition for Faithful Vision-Language Concept (FVLC) and a methodology for constructing an FVLC that satisfies four critical properties. Our experiments on four benchmark datasets (CIFAR-10, CIFAR-100, CUB, Places365) demonstrate that FVLC outperforms baselines regarding stability against input and concept set perturbations (WP1, WP2, IP), with minimal accuracy degradation compared to vanilla Label-free CBM.
Motivation: instability under perturbation
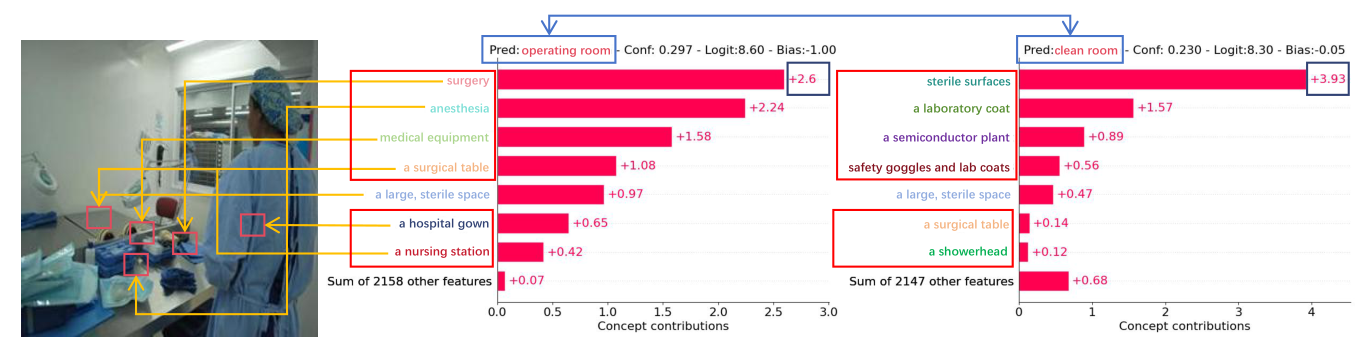
Example using the Places365 dataset. The leftmost figure displays the input image; the adjacent one shows the concept output without perturbations. The figure on the right shows the concept output after applying concept words and input perturbations, resulting in noticeable changes: shifts in concept positioning along the ordinate and adjustments in the ranks of their weights (e.g. the concept “surgery”). The prediction has also changed under slight perturbations.
Pipeline overview
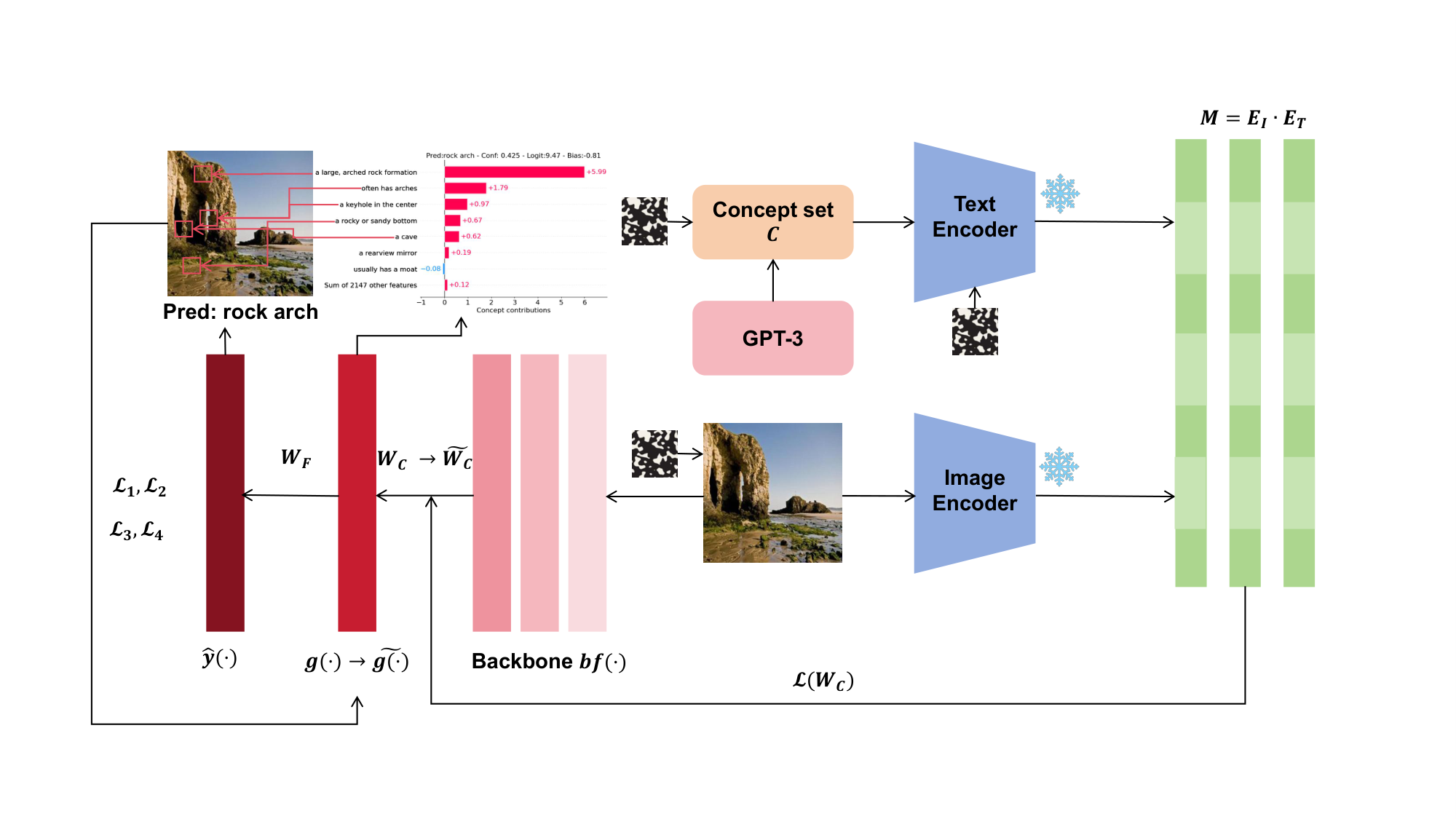
An overview of our pipeline for creating FVLC. For the concept set $\mathcal{C}$ output by GPT-3, it is input into the text encoder of CLIP to obtain $E_T$. The input image is processed by the image encoder of CLIP to obtain $E_I$. The image is fed into the backbone to extract image features. The obtained activation matrix $M$ from $E_I$ and $E_T$ is used to learn the mappings $g(\cdot)$ and $W_c$ from the feature space to the concept space. The mapping $W_F$ from the concept space to the image category is learned. Then $\mathcal{L}_1$/$\mathcal{L}_2$/$\mathcal{L}_3$/$\mathcal{L}_4$ are employed to enhance the model’s faithfulness ($W_c \rightarrow \tilde{W}_c$, $g(x) \rightarrow \tilde{g}(x)$). We introduce noise interference in the concept set, text encoder, and input image to validate the faithfulness of our model. The box mixed with black and white dots represents the noise; snowflakes represent frozen parameters.
Step 1: Concept set creation

Example of our Step 1 (concept set creation via GPT-3).
Theory and methodology
Top-$k$ overlaps
For vector $x \in \mathbb{R}^d$, the set of top-$k$ components is
\[T_k(x) = \bigl\{ i \in [d] : \bigl| \{ j : x_j \geq x_i \} \bigr| \leq k \bigr\}.\]The top-$k$ overlap between two vectors $x$, $x’$ is the overlapping ratio
\[V_k(x, x') = \frac{1}{k} \bigl| T_k(x) \cap T_k(x') \bigr|.\]Faithful Vision-Language Concept (Definition 1)
Under the same concept space (set of concepts generated by GPT-3 at one time), a matrix $\tilde{W}_c$ is a $(D, R, \alpha, \beta, k_1, k_2)$-Faithful Vision-Language Concept (FVLC) for the vanilla concept if for any input $x$:
- Similarity of explanation: $V_{k_1}(\tilde{g}(x), g(x)) \geq \beta_1$ for some $\beta_1 \in [0,1]$.
- Stability of explanation: $V_{k_2}(\tilde{g}(x), \tilde{g}(x)+\rho) \geq \beta_2$ for some $\beta_2 \in [0,1]$ and all $|\rho| \leq R_1$.
- Closeness of prediction: $D(y(x, \tilde{c}), y(x, c)) \leq \alpha_1$ for some $\alpha_1 \geq 0$, where $D$ is a probability distance (e.g. KL divergence).
- Stability of prediction: $D(y(x, \tilde{c}), y(x, \tilde{c}+\delta)) \leq \alpha_2$ for all $|\delta| \leq R_2$.
Here $\tilde{g}(x) = \tilde{W}_c \, \text{bf}(x)$, $y(x, c) = W_F g(x)$, $y(x, \tilde{c}) = W_F \tilde{g}(x)$, and $y(x, \tilde{c}+\delta) = W_F (\tilde{g}(x)+\delta)$.
Min-max objective (Equation 7)
We freeze the image encoder and solve a min-max problem. The overall objective is
\[\min_{\tilde{W}_c} \mathbb{E}_x\Bigl[ \lambda_1 \underbrace{D(y(x, \tilde{c}), y(x, c))}_{\mathcal{L}_1} + \lambda_2 \underbrace{\mathcal{L}_{k_1}(\tilde{g}(x), g(x))}_{\mathcal{L}_2} + \lambda_3 \underbrace{\max_{\|\delta\| \leq R_2} D(y(x, \tilde{c}), y(x, \tilde{c}+\delta))}_{\mathcal{L}_3} + \lambda_4 \underbrace{\max_{\|\rho\| \leq R_1} \mathcal{L}_{k_2}(\tilde{g}(x), \tilde{g}(x)+\rho)}_{\mathcal{L}_4} \Bigr],\]where $\mathcal{L}_k$ is a differentiable surrogate for $-V_k(\cdot, \cdot)$ and $D$ is Kullback–Leibler divergence. We use PGD for the inner maximization over $\delta$ and $\rho$, and gradient descent for the outer minimization over $\tilde{W}_c$.
Perturbations and metrics
- WP1 (Word Perturbation 1): Replace 5% or 10% of concept words with synonyms (via GPT-3).
- WP2 (Word Perturbation 2): Add Gaussian noise $\mathcal{N}(0, \sigma)$ to the text embedding with $\sigma = 0.001$.
- IP (Input Perturbation): Add perturbation of radius $\sigma = 0.001$ to the normalized input image.
TCPC (Total Concept Perturbation Change): $\texttt{TCPC}(c_1, c_2) = | c_1 - c_2 | / | c_1 |$ (stability of concept weights).
TOPC (Total Output Perturbation Change): $\texttt{TOPC}(y_1, y_2) = | y_1 - y_2 | / | y_1 |$ (stability of predictions).
Lower is more stable.
Main results
Table 1: Accuracy (%)
| Method | CIFAR10 | CIFAR100 | CUB | Places365 |
|---|---|---|---|---|
| Standard (no interpretability) | 88.80 | 70.10 | 76.70 | 48.56 |
| P-CBM (CLIP) | 84.50 | 56.00 | N/A | N/A |
| Label-free CBM | 86.32 | 65.42 | 74.23 | 43.63 |
| WP1(10%) – base | 86.25 | 65.09 | 73.97 | 43.67 |
| WP1(10%) – FVLC | 86.39 | 64.90 | 73.92 | 43.62 |
| WP2 – base | 86.41 | 65.16 | 73.96 | 43.54 |
| WP2 – FVLC | 86.22 | 65.34 | 74.44 | 44.55 |
| IP – base | 86.62 | 65.36 | 74.39 | 43.64 |
| IP – FVLC | 86.88 | 65.29 | 74.01 | 43.71 |
Table 2: Stability (TCPC / TOPC) — lower is better
| Method | CIFAR10 | CIFAR100 | CUB | Places365 |
|---|---|---|---|---|
| WP1(10%) – base | 1.99E-01 / 8.36E-02 | 1.94E-01 / 1.31E-01 | 2.32E-01 / 3.41E-01 | 2.26E-01 / 1.14E-01 |
| WP1(10%) – FVLC | 1.19E-03 / 7.40E-03 | 3.67E-03 / 4.55E-03 | 1.19E-02 / 1.53E-03 | 1.39E-03 / 1.25E-03 |
| WP2 – base | 1.53E-01 / 4.99E-02 | 1.36E-01 / 6.67E-02 | 1.43E-01 / 1.73E-01 | 1.40E-01 / 6.37E-02 |
| WP2 – FVLC | 1.10E-02 / 8.72E-03 | 3.35E-03 / 4.55E-03 | 1.05E-02 / 1.53E-03 | 1.55E-03 / 1.29E-03 |
| IP – base | 1.68E-01 / 6.28E-02 | 1.38E-01 / 8.81E-02 | 1.71E-01 / 2.23E-01 | 1.73E-01 / 8.09E-02 |
| IP – FVLC | 8.02E-03 / 8.29E-03 | 3.24E-03 / 4.56E-03 | 1.04E-02 / 1.59E-03 | 1.50E-03 / 1.25E-03 |
Ablation (Table 3)
Ablation over $\mathcal{L}_2$, $\mathcal{L}_3$, $\mathcal{L}_4$ shows that all three contribute; using all three (✓✓✓) yields the best TCPC/TOPC.
Visualizations: concept weights and final-layer weights
One sample per dataset (overview)
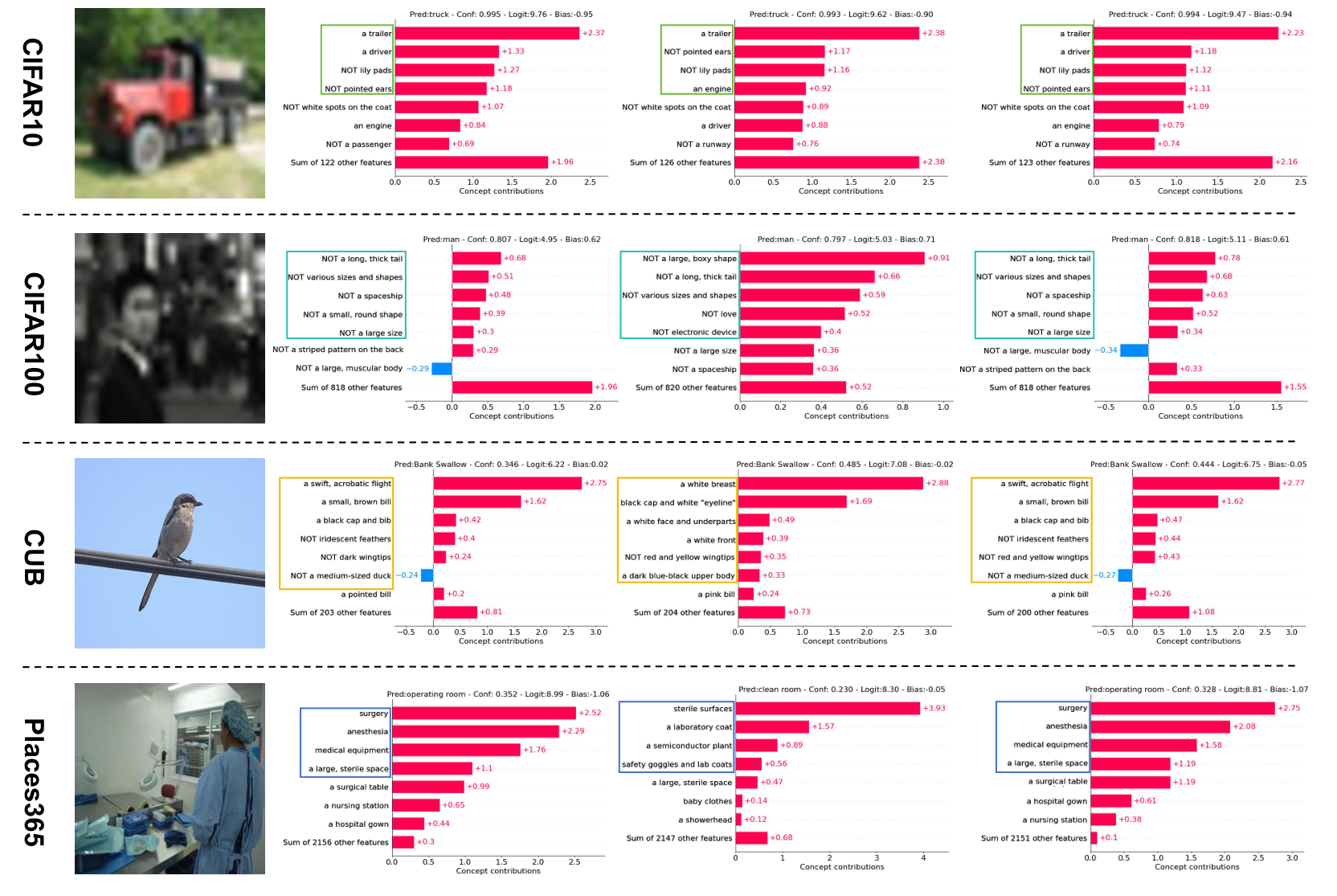
The visualizations for concept weights and final layer weights on one sample from each dataset. From left to right: input image $x$, concept weight visualization without perturbation ($c$), with perturbation ($c+\delta$), and optimized concept weight visualization with perturbation ($\tilde{c}+\delta$).
CIFAR-10
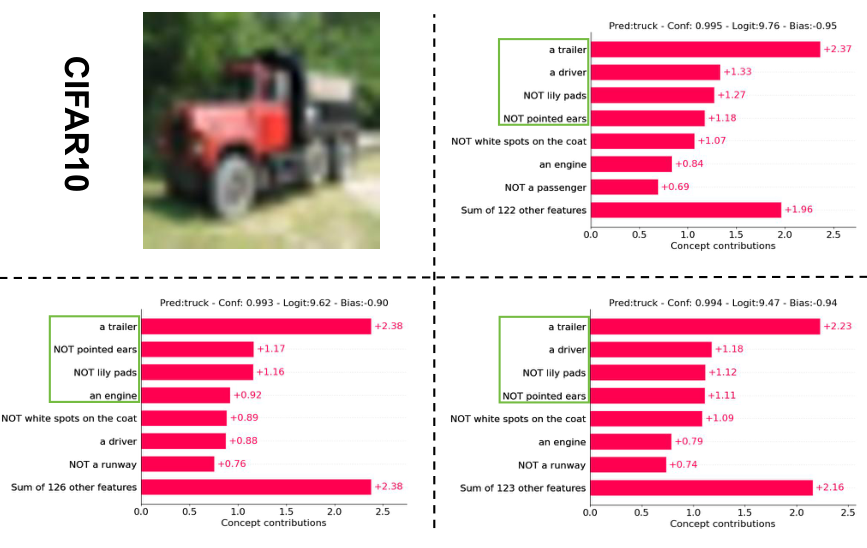
Concept weights and final layer weights on one sample from CIFAR-10. Top left: input image; top right: concept without perturbation; bottom left: with perturbation; bottom right: optimized with perturbation.
CIFAR-100
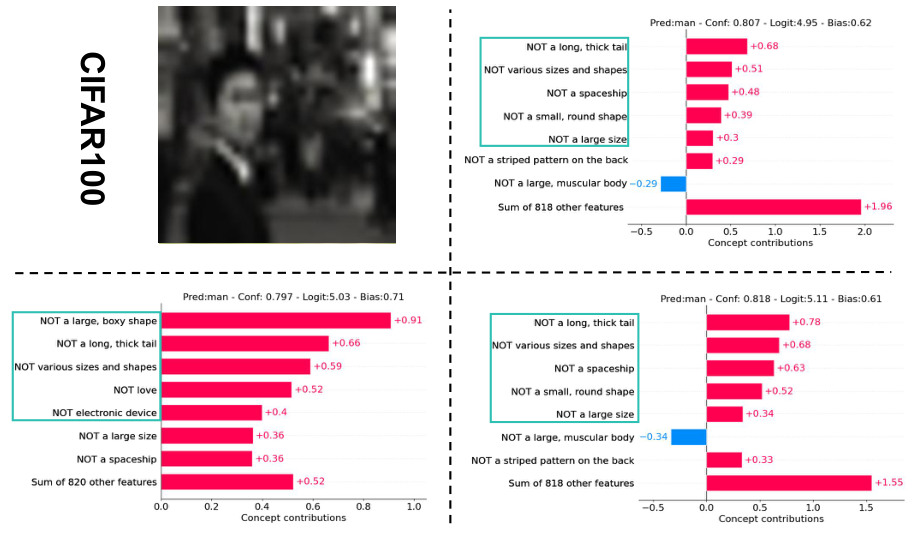
Same layout for one sample from CIFAR-100.
CUB
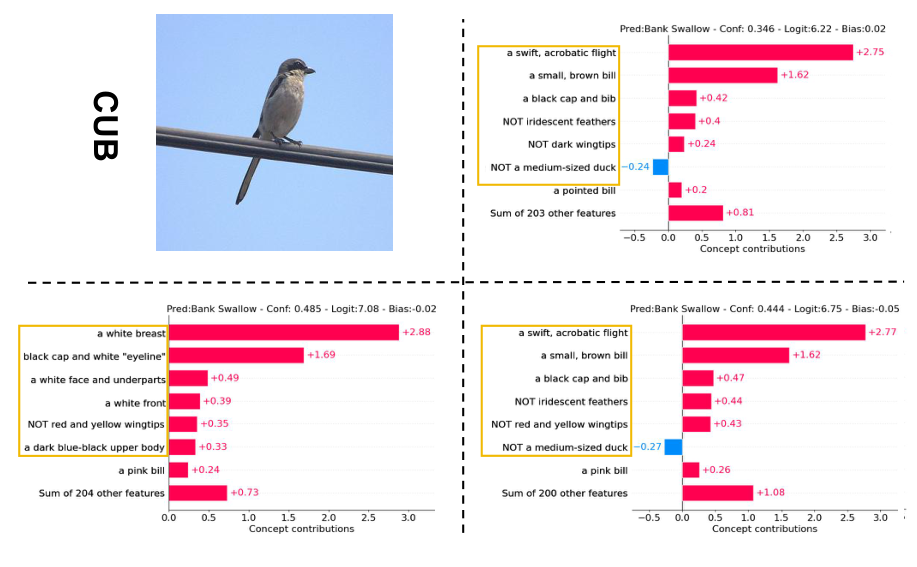
Same layout for one sample from CUB.
Places365
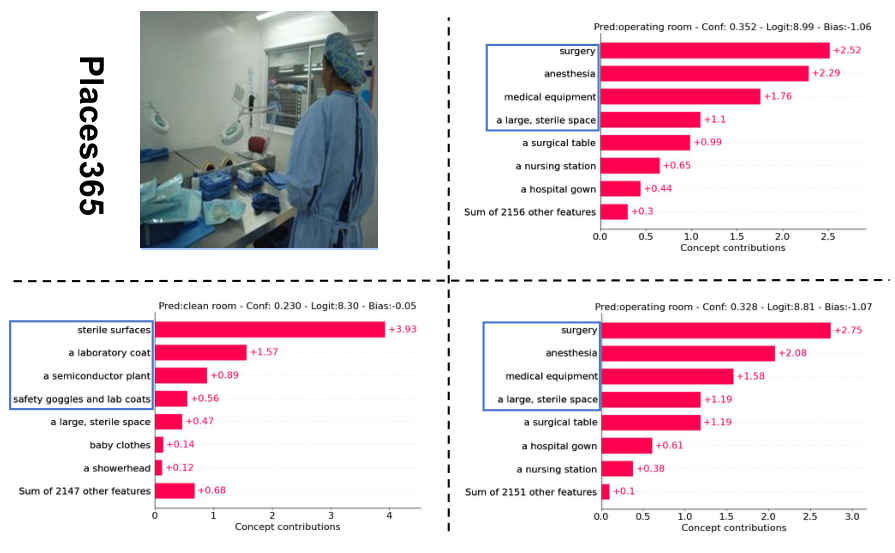
Same layout for one sample from Places365.
HAM10000 (Appendix)
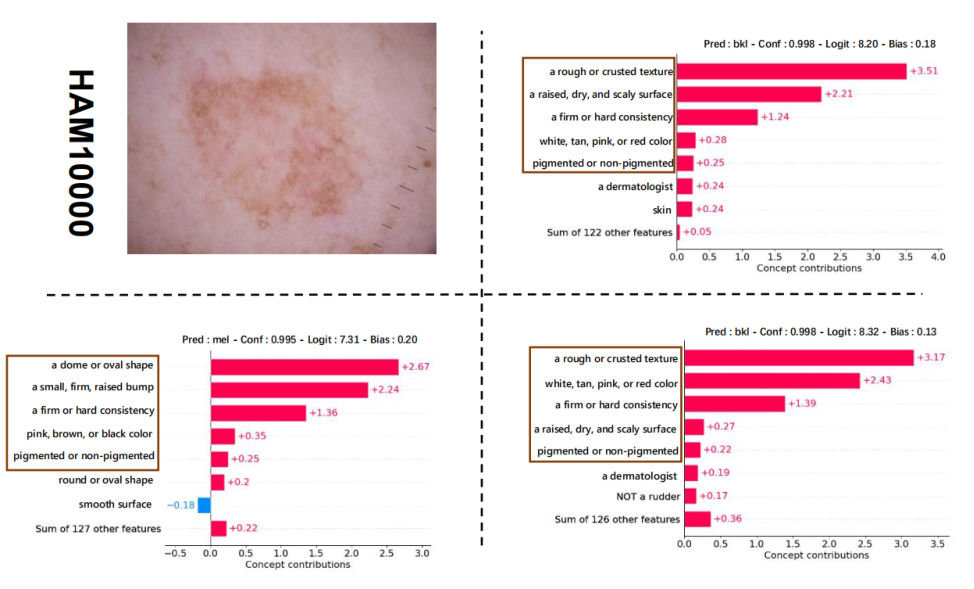
Explanations for one randomly chosen input image for our model trained on HAM10000. Same layout: input image, concept without perturbation, with perturbation, and optimized with perturbation.
Code and data
- Repository: https://github.com/xll0328/FVLC
- Datasets: CIFAR-10, CIFAR-100, CUB-200-2011, Places365 (concept sets under
data/concept_sets/). - Training:
train_cbm.py(base Label-free CBM),train_fcbm_all.py(full FVLC),train_fcbm_projonly.py(projection-only FVLC). See README in the repo for setup and commands.
Citation
@inproceedings{lai2023faithful,
title={Faithful Vision-Language Interpretation via Concept Bottleneck Models},
author={Lai, Songning and Hu, Lijie and Wang, Junxiao and Berti-Equille, Laure and Wang, Di},
booktitle={The Twelfth International Conference on Learning Representations (ICLR)},
year={2024}
}