
ACM MM 2025 · CCF A · Core A*
FTS: From Guesswork to Guarantee — Faithful Multimedia Web Forecasting with TimeSieve
Official project page
TL;DR
FTS strengthens TimeSieve with faithfulness-aware optimization (Sib/Cps/Snp), improving forecasting robustness to seed/input/layer perturbations while maintaining SOTA accuracy.
Authors: Songning Lai, Ninghui Feng, Jiechao Gao, Hao Wang, Haochen Sui, Xin Zou, Jiayu Yang, Wenshuo Chen, Lijie Hu, Hang Zhao, Xuming Hu, Yutao Yue
Framework (from paper)
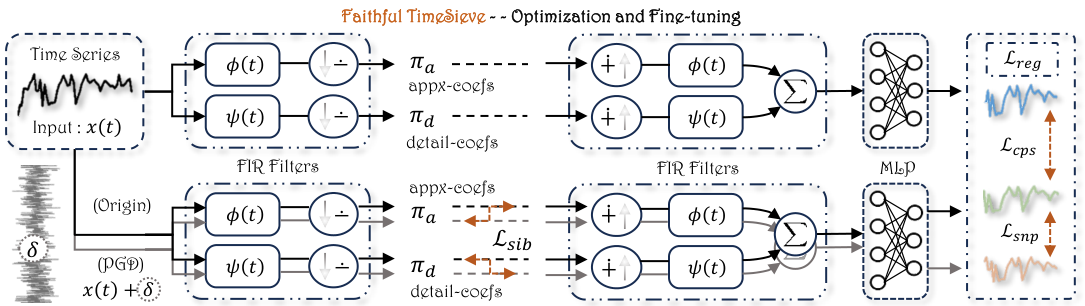
Framework of our proposed Faithful TimeSieve (FTS).
Abstract
The domain of time series forecasting has gained significant attention due to its critical applications in multimedia-rich web traffic (video streaming workloads, dynamic content delivery) and cross-platform advertisement click predictions. While TimeSieve has demonstrated strong capabilities in predicting web visitation metrics, it suffers from critical unfaithfulness issues: sensitivity to random seeds, input noise, layer noise, and parameter perturbations. We propose Faithful TimeSieve (FTS), an enhanced framework that systematically detects and mitigates unfaithfulness in TimeSieve, significantly enhancing its stability and consistency. Experimental results demonstrate that FTS substantially improves the model’s faithfulness and achieves SOTA on multiple datasets, setting a new standard for temporal forecasting methods. This advancement is particularly crucial for web traffic forecasting where prediction accuracy directly impacts operational decisions.
Key Contributions
- Comprehensive Faithfulness Assessment — In-depth analysis of TimeSieve identifying factors that affect its faithfulness (random seeds, input/layer/parameter perturbations).
- Definition of Faithful TimeSieve — Rigorous (α₁, α₂, β, δ, R₁, R₂)-Faithful definition with three attributes: Sib, Cps, Snp.
- Multimedia-aware Robustness Framework — Min-max optimization with PGD and content-adaptive stabilization; framework transfers to other time series models (e.g. PatchTST).
- Theoretical and Experimental Validation — Bounds for Sib/Cps/Snp and extensive experiments on Wiki, ETTh1, Exchange; FTS achieves SOTA and strong robustness.
Motivation: Why Faithfulness?
- Stability under random seeds — Performance should not vary drastically (e.g. up to ~50% in our study) across different training runs.
- Robustness to input perturbations — Minor input noise led to ~30% performance decline in TimeSieve; FTS recovers via optimization.
- Robustness to layer/parameter perturbations — Model behavior should remain consistent under parameter noise (e.g. IFCB layer).
FTS: Three Attributes (formal)
Sib (Similarity in IB Space): Distance D₁ between approximation/detail representations under perturbation is at most β, for all ‖δ‖ ≤ R₁.
\[D_1(\hat{\pi}_a(x(t)), \hat{\pi}_a(x(t)+\delta)) \leq \beta \quad \text{(and similarly for } \hat{\pi}_d\text{).}\]Cps (Consistency in Prediction Space): Distance D₂ between predictions under fine-tuned weights and original weights is at most α₁.
\[D_2(y(x(t), \tilde{\omega}), y(x(t), \omega)) \leq \alpha_1.\]Snp (Stability in Noise Perturbations): Distance D₃ between predictions under perturbed input is at most α₂ for all ‖δ‖ ≤ R₂.
\[D_3(y(x(t), \tilde{\omega}), y(x(t)+\delta, \tilde{\omega})) \leq \alpha_2.\]Framework & Loss
Total training objective (Lreg = regression loss, LIB = TimeSieve IB loss; Lsib, Lcps, Lsnp = faithfulness auxiliary losses):
\[\mathcal{L} = \mathcal{L}_{\mathrm{reg}} + \mathcal{L}_{\mathrm{IB}} + \lambda_1 \mathcal{L}_{\mathrm{sib}} + \lambda_2 \mathcal{L}_{\mathrm{cps}} + \lambda_3 \mathcal{L}_{\mathrm{snp}}\]PGD finds worst-case perturbation δ; then fine-tuned weights are updated by gradient descent.
Theory (from paper)
Preliminaries (TimeSieve). The Wavelet Decomposition Block decomposes input x(t) into approximation coefficients π_a (low-frequency) and detail coefficients π_d (high-frequency):
\[\pi_a = \int_{-\infty}^{\infty} x(t) \phi(t)\, dt, \qquad \pi_d = \int_{-\infty}^{\infty} x(t) \psi(t)\, dt,\]where φ(t) and ψ(t) are the scaling and wavelet functions. The reconstruction is y = MLP(∑ π̂_a φ(t) + ∑ π̂_d ψ(t)), with π̂_a, π̂_d the filtered coefficients from the IFCB. The Information Filtering and Compression Block (IFCB) minimizes I(π_i; z) − β·I(z; π̂_i) and uses IB loss:
\[\mathcal{L}_{\mathrm{IB}} = D_{\mathrm{KL}}[\mathcal{N}(\mu_z, \Sigma_z) \| \mathcal{N}(0, I)] + D_{\mathrm{KL}}[p(z) \| p(z|i)].\]The original TimeSieve loss is Lreg + LIB.
Definition (Faithful TimeSieve). A TimeSieve model is (α₁, α₂, β, δ, R₁, R₂)-Faithful if for any input x(t) it satisfies: (i) Sib: D₁ between approximation/detail coefficients at x(t) and at x(t)+δ is ≤ β for all ‖δ‖ ≤ R₁; (ii) Cps: D₂(y(x(t), ω̃), y(x(t), ω)) ≤ α₁; (iii) Snp: D₃(y(x(t), ω̃), y(x(t)+δ, ω̃)) ≤ α₂ for all ‖δ‖ ≤ R₂. Here ω = original weights, ω̃ = fine-tuned weights; D₁, D₂, D₃ are distances/divergences, ‖·‖ a norm.
Definition (μ-Rényi divergence). For distributions P, Q and μ ∈ (1, ∞):
\[D_\mu(P \| Q) = \frac{1}{\mu-1} \log \mathbb{E}_{x\sim Q}\left(\frac{P(x)}{Q(x)}\right)^\mu.\]Theorem 1 (Upper bound for Sib). Under (α₁, α₂, β, δ, R₁, R₂)-Faithful TimeSieve, if the distance between IB representations at x(t) and at x(t)+δ is at least β for i ∈ {a, d}, then for all x(t)′ = x(t)+δ with ‖x(t)−x(t)′‖ ≤ R₁:
\[\|f(z, \hat{\pi}_i; \theta_d) - f(z, \hat{\pi}_i'; \theta_d)\| \leq c\delta,\]where the primed representation is at x(t)+δ and c is a constant. (Proof in Appendix.)
Theorem 2 (Lower bound for Sib). Under the same setting with IB space measured by Rényi divergence D_μ and ‖·‖, if δ ∼ N(0, σ²), then for any μ ∈ (1, ∞):
\[\sigma^2 \geq \max\left\{ \delta,\; \frac{\mu R_1^2}{2\beta} \right\}.\]When μ R₁²/(2σ²) ≤ β, FTS satisfies Sib. (Proof in Appendix.)
Theorem 3 (Consistency in prediction space). Under (α₁, α₂, β, δ, R₁, R₂)-Faithful TimeSieve, for the model y(·):
\[D_2(y(x(t), \tilde{\omega}) - y(x(t), \omega)) \leq c\delta = \alpha_1,\]where c is a constant and D₂ can be a norm ‖·‖.
Definition (Stable Diameter). If R₁ and α₁ are bounded, the Stable Diameter R₂ is:
\[R_2 = \sup_{R \in \mathcal{R}} \bigl\{ R \leq R_1 : D_2(y(x(t), \tilde{\omega}) - y(x(t), \omega)) \leq \alpha_1 \bigr\},\]with ℛ the set of potential diameters.
Theorem 4 (Stability in noise perturbations). Under (α₁, α₂, β, δ, R₁, R₂)-Faithful TimeSieve, for all R in ℛ:
\[D_3(y(x(t), \tilde{\omega}), y(x(t)+\delta, \tilde{\omega})) \leq \alpha_2, \quad \|\delta\| \leq R_2,\]where D₃ can be a norm and α₂ ≤ α₁ (given by the stable diameter).
Min-max objective. FTS is built from the following (λ_i are hyperparameters):
\(\max_{\|\delta\| \leq R} \lambda_1 (\beta - D_1(\hat{\pi}_a(x(t)), \hat{\pi}_a(x(t)+\delta))) + \max_{\|\delta\| \leq R} \lambda_1 (\beta - D_1(\hat{\pi}_d(x(t)), \hat{\pi}_d(x(t)+\delta)))\) \(+ \min_{\tilde{\omega}} \mathbb{E}_x \bigl[ \lambda_2 (D_2(y(x(t), \tilde{\omega}), y(x(t), \omega)) - \alpha_1) + \max_{\|\delta\| \leq R} \lambda_3 (D_3(y(x(t), \tilde{\omega}), y(x(t)+\delta, \tilde{\omega})) - \alpha_2) \bigr].\)
PGD step. At the p-th iteration, perturbation is updated by gradient ascent on the sum of D₁, D₂, D₃ (then projected to ‖δ‖ ≤ R); then ω̃ is updated by gradient descent. After combining with Lreg and LIB we obtain the full loss above.
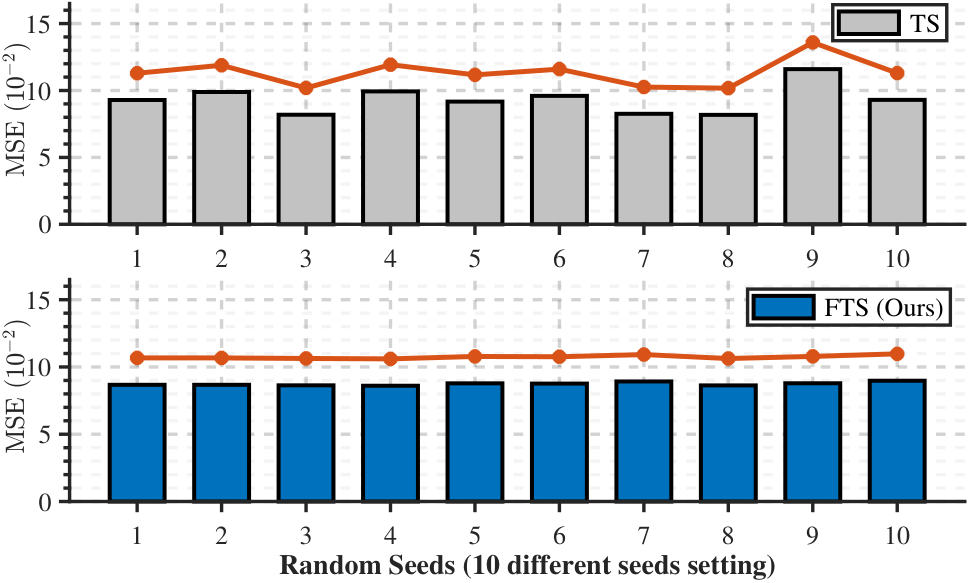
Figure 1: TS vs FTS under 10 random seeds (from paper)
Ten different random seeds are selected to train TimeSieve (TS) and Faithful TimeSieve (FTS) respectively. FTS maintains more consistent performance across seeds.
Main Results
Table 1: Forecasting results (no perturbation)
Forecast length H ∈ {48, 96, 144, 192}, lookback T = 2H. Best in red, second best in blue.
| Dataset | H | FTS (MAE / MSE) | TS (MAE / MSE) | Koopa | PatchTST | TSMixer | DLinear | NSTformer | LightTS | Autoformer |
|---|---|---|---|---|---|---|---|---|---|---|
| Wiki | 48 | 0.305 / 0.467 | 0.323 / 0.490 | 0.314 / 0.496 | 0.312 / 0.495 | 0.318 / 0.490 | 0.350 / 0.517 | 0.307 / 0.508 | 0.313 / 0.494 | 0.315 / 0.522 |
| 96 | 0.262 / 0.430 | 0.266 / 0.433 | 0.283 / 0.451 | 0.280 / 0.445 | 0.277 / 0.435 | 0.286 / 0.462 | 0.303 / 0.633 | 0.287 / 0.460 | 0.348 / 0.550 | |
| 144 | 0.268 / 0.445 | 0.270 / 0.447 | 0.284 / 0.459 | 0.280 / 0.451 | 0.320 / 0.496 | 0.287 / 0.458 | 0.309 / 0.521 | 0.291 / 0.471 | 0.360 / 0.616 | |
| 192 | 0.273 / 0.447 | 0.276 / 0.452 | 0.294 / 0.467 | 0.289 / 0.461 | 0.370 / 0.644 | 0.289 / 0.463 | 0.339 / 0.605 | 0.301 / 0.490 | 0.373 / 0.629 | |
| ETTh1 | 48 | 0.360 / 0.340 | 0.361 / 0.341 | 0.385 / 0.364 | 0.375 / 0.342 | 0.432 / 0.407 | 0.372 / 0.342 | 0.465 / 0.614 | 0.406 / 0.404 | 0.432 / 0.678 |
| 96 | 0.383 / 0.376 | 0.384 / 0.376 | 0.411 / 0.406 | 0.395 / 0.377 | 0.473 / 0.466 | 0.395 / 0.380 | 0.498 / 0.653 | 0.431 / 0.435 | 0.496 / 0.578 | |
| 144 | 0.396 / 0.391 | 0.397 / 0.393 | 0.426 / 0.424 | 0.412 / 0.394 | 0.528 / 0.537 | 0.401 / 0.394 | 0.536 / 0.602 | 0.442 / 0.453 | 0.521 / 0.761 | |
| 192 | 0.406 / 0.402 | 0.408 / 0.402 | 0.434 / 0.430 | 0.437 / 0.416 | 0.592 / 0.642 | 0.416 / 0.408 | 0.543 / 0.684 | 0.457 / 0.471 | 0.568 / 0.598 | |
| Exchange | 48 | 0.139 / 0.042 | 0.140 / 0.043 | 0.149 / 0.046 | 0.145 / 0.048 | 0.149 / 0.046 | 0.145 / 0.046 | 0.187 / 0.073 | 0.159 / 0.067 | 0.205 / 0.124 |
| 96 | 0.196 / 0.084 | 0.197 / 0.086 | 0.211 / 0.092 | 0.204 / 0.090 | 0.211 / 0.092 | 0.223 / 0.089 | 0.294 / 0.159 | 0.247 / 0.168 | 0.778 / 0.409 | |
| 144 | 0.242 / 0.123 | 0.243 / 0.124 | 0.265 / 0.141 | 0.265 / 0.138 | 0.265 / 0.141 | 0.256 / 0.133 | 0.375 / 0.292 | 0.272 / 0.310 | 0.680 / 0.671 | |
| 192 | 0.287 / 0.170 | 0.292 / 0.179 | 0.329 / 0.212 | 0.298 / 0.181 | 0.329 / 0.212 | 0.301 / 0.182 | 0.464 / 0.494 | 0.354 / 0.403 | 0.979 / 0.544 |
Table 2: Random seed stability (Exchange, 96-step, MSE)
Baseline seed 2021*. Preference (%) quantifies combined performance and stability (higher = FTS preferred).
| Seed | TS (MSE) | FTS (MSE) | Preference (%) |
|---|---|---|---|
| 2021* | 0.0929 | 0.0868 | — |
| 2022 | 0.0989 | 0.0867 | 99.61% |
| 2023 | 0.0819 | 0.0864 | 96.09% |
| 2024 | 0.0993 | 0.0860 | 87.95% |
| 2025 | 0.0917 | 0.0878 | 4.49% |
| 2026 | 0.0960 | 0.0876 | 69.27% |
| 2027 | 0.0826 | 0.0892 | 74.16% |
| 2028 | 0.0818 | 0.0863 | 95.81% |
| 2029 | 0.1160 | 0.0879 | 94.69% |
| 2030 | 0.0897 | 0.0898 | 1.53% |
Table 3: Robustness under perturbation (MAE / MSE)
NP = no perturbation, NPO = NP with FTS optimization, IP = input perturbation, IPO = IP with optimization, ILP = intermediate-layer perturbation, ILPO = ILP with optimization. Bold = FTS (improved).
| Dataset | H | NP | NPO | IP | IPO | ILP | ILPO |
|---|---|---|---|---|---|---|---|
| Wiki | 48 | 0.323/0.490 | 0.305/0.467 | 0.433/0.608 | 0.367/0.531 | 0.453/0.590 | 0.399/0.551 |
| Wiki | 96 | 0.266/0.433 | 0.262/0.430 | 0.405/0.575 | 0.321/0.482 | 0.367/0.681 | 0.329/0.613 |
| Wiki | 144 | 0.270/0.447 | 0.268/0.445 | 0.409/0.600 | 0.326/0.542 | 0.375/0.967 | 0.305/0.723 |
| Wiki | 192 | 0.276/0.452 | 0.273/0.447 | 0.408/0.580 | 0.327/0.493 | 0.404/1.548 | 0.366/1.165 |
| ETTh1 | 48 | 0.361/0.341 | 0.360/0.340 | 0.386/0.375 | 0.376/0.361 | 0.437/0.456 | 0.392/0.392 |
| ETTh1 | 96 | 0.384/0.377 | 0.383/0.376 | 0.411/0.424 | 0.404/0.408 | 0.415/0.422 | 0.401/0.397 |
| ETTh1 | 144 | 0.397/0.393 | 0.396/0.391 | 0.422/0.437 | 0.413/0.422 | 0.483/0.520 | 0.447/0.472 |
| ETTh1 | 192 | 0.408/0.404 | 0.406/0.402 | 0.431/0.445 | 0.420/0.426 | 0.443/0.451 | 0.428/0.430 |
| Exchange | 48 | 0.140/0.043 | 0.139/0.042 | 0.220/0.102 | 0.186/0.073 | 0.160/0.045 | 0.148/0.044 |
| Exchange | 96 | 0.197/0.086 | 0.196/0.084 | 0.265/0.131 | 0.237/0.104 | 0.221/0.102 | 0.202/0.092 |
| Exchange | 144 | 0.243/0.124 | 0.242/0.123 | 0.312/0.175 | 0.271/0.141 | 0.292/0.164 | 0.253/0.149 |
| Exchange | 192 | 0.292/0.179 | 0.287/0.170 | 0.345/0.239 | 0.307/0.178 | 0.331/0.205 | 0.304/0.190 |
Table 4: Loss ablation (ETTh1 & Exchange, MAE / MSE)
Ltotal = Lreg + LIB + λ₁Lsib + λ₂Lcps + λ₃Lsnp. Best in red, second in blue. Columns: full loss, no Lsnp, no Lcps, no Lsib, and other ablations.
| Dataset | H | Ltotal | no Lsnp | no Lcps | no Lsib | no (cps+sib) | no (snp+sib) | no (snp+cps) | no (all 3) |
|---|---|---|---|---|---|---|---|---|---|
| ETTh1 | 48 | 0.376/0.361 | 0.383/0.370 | 0.381/0.363 | 0.378/0.361 | 0.381/0.365 | 0.383/0.370 | 0.384/0.372 | 0.382/0.371 |
| ETTh1 | 96 | 0.404/0.408 | 0.409/0.419 | 0.405/0.410 | 0.404/0.408 | 0.404/0.410 | 0.410/0.419 | 0.411/0.421 | 0.410/0.420 |
| ETTh1 | 144 | 0.413/0.422 | 0.423/0.431 | 0.413/0.423 | 0.417/0.422 | 0.414/0.422 | 0.423/0.431 | 0.423/0.430 | 0.420/0.429 |
| ETTh1 | 192 | 0.420/0.426 | 0.425/0.433 | 0.428/0.431 | 0.423/0.426 | 0.425/0.430 | 0.428/0.433 | 0.430/0.433 | 0.427/0.429 |
| Exchange | 48 | 0.186/0.073 | 0.195/0.078 | 0.190/0.084 | 0.191/0.074 | 0.190/0.085 | 0.195/0.078 | 0.197/0.083 | 0.195/0.080 |
| Exchange | 96 | 0.237/0.104 | 0.238/0.112 | 0.242/0.126 | 0.235/0.106 | 0.242/0.126 | 0.238/0.112 | 0.244/0.139 | 0.241/0.137 |
| Exchange | 144 | 0.271/0.141 | 0.277/0.150 | 0.281/0.177 | 0.270/0.139 | 0.281/0.178 | 0.278/0.150 | 0.280/0.192 | 0.280/0.188 |
| Exchange | 192 | 0.307/0.178 | 0.309/0.191 | 0.317/0.236 | 0.305/0.180 | 0.318/0.236 | 0.310/0.188 | 0.314/0.254 | 0.314/0.254 |
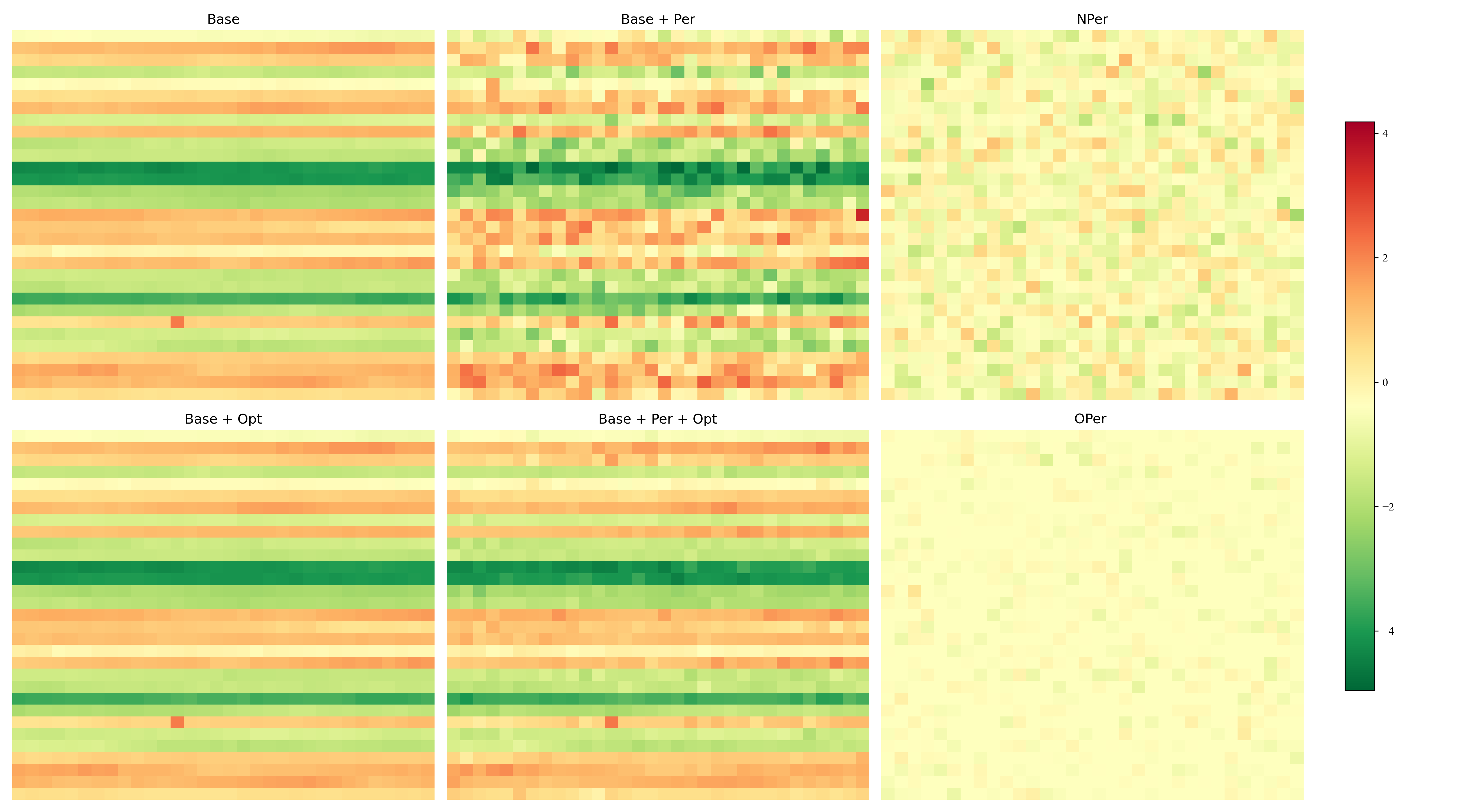
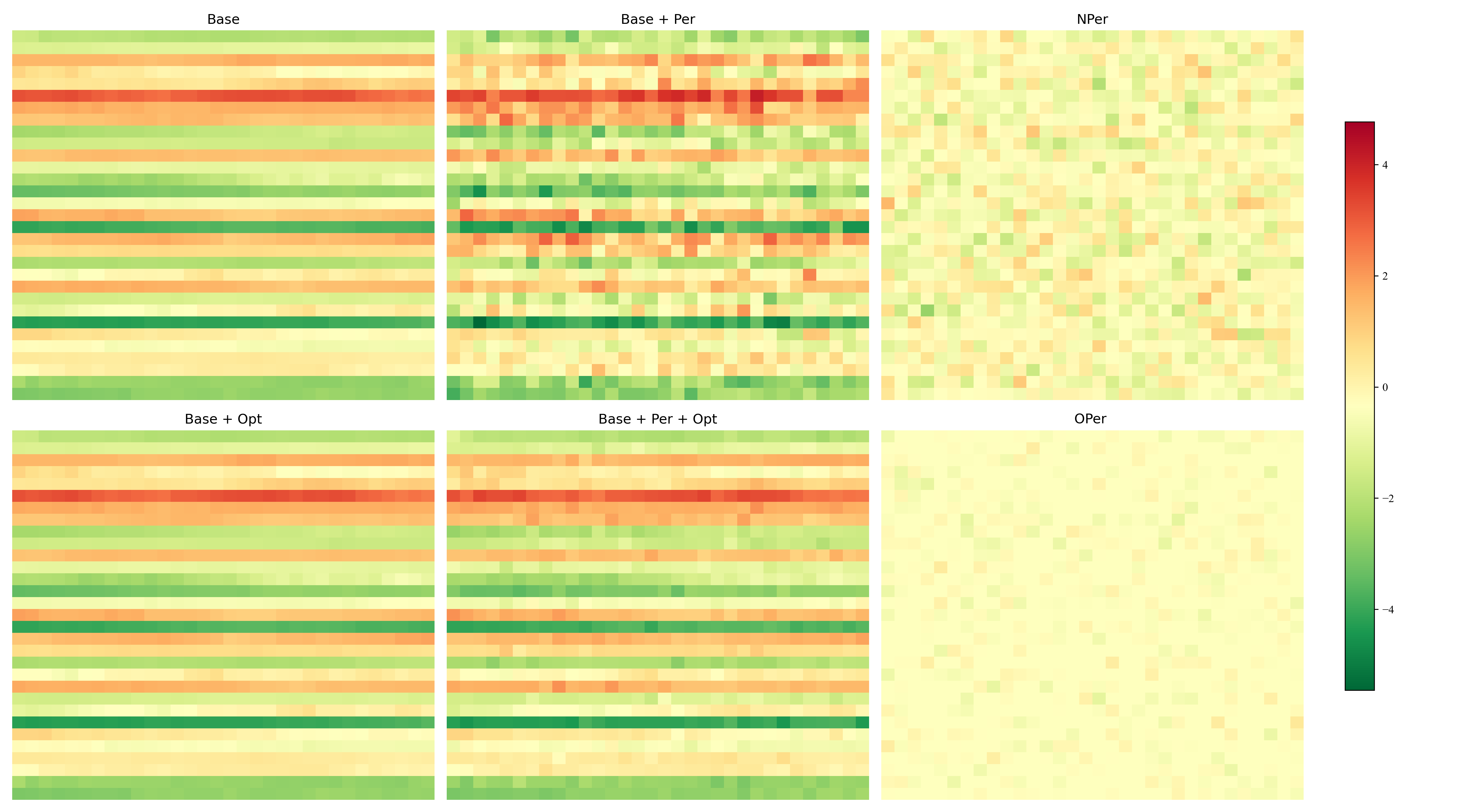
Heatmaps (from paper): prediction length 48, 96, 144, 192
Intermediate layer tensors on Exchange dataset (MSE). Nper vs Oper shows effectiveness of optimization.
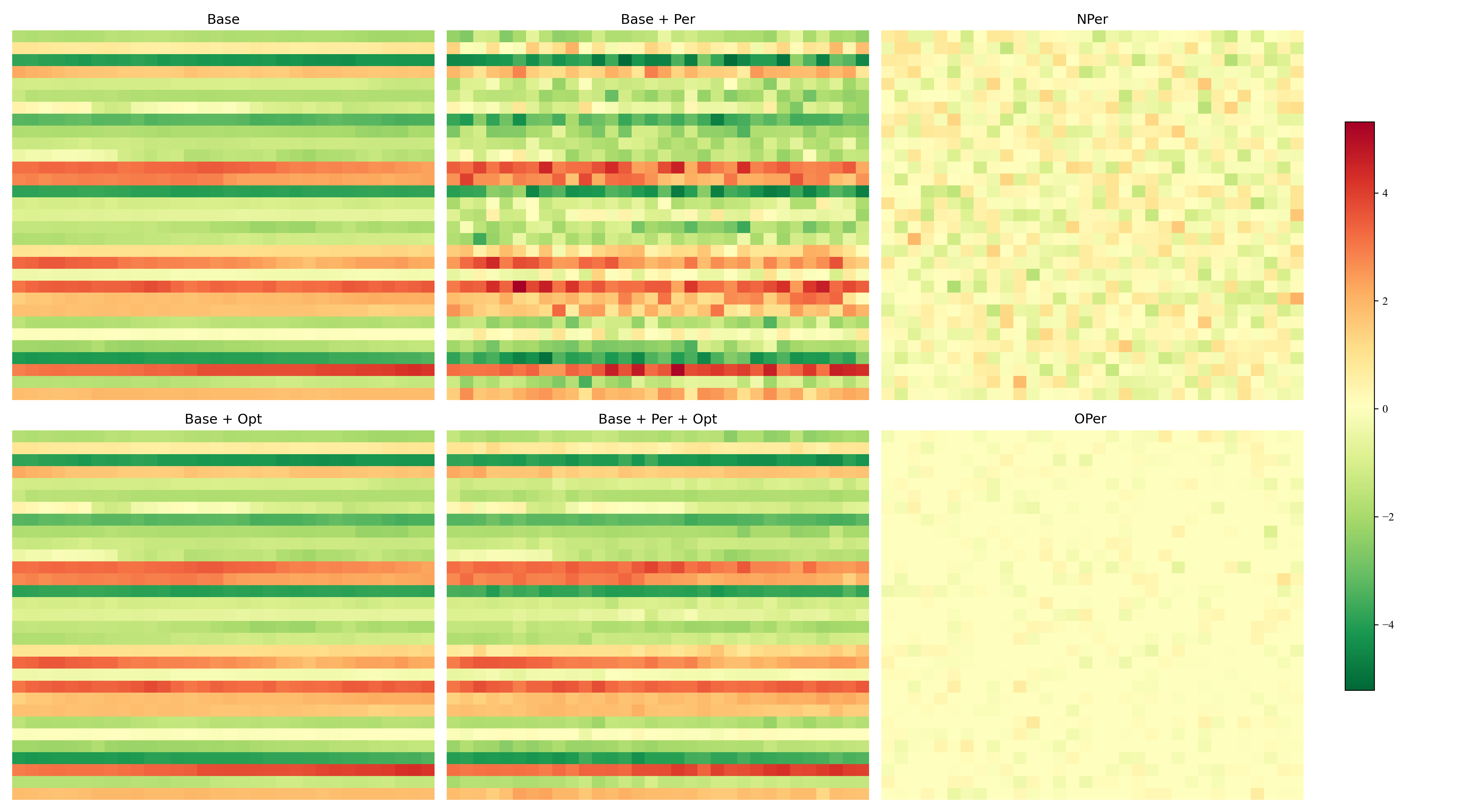
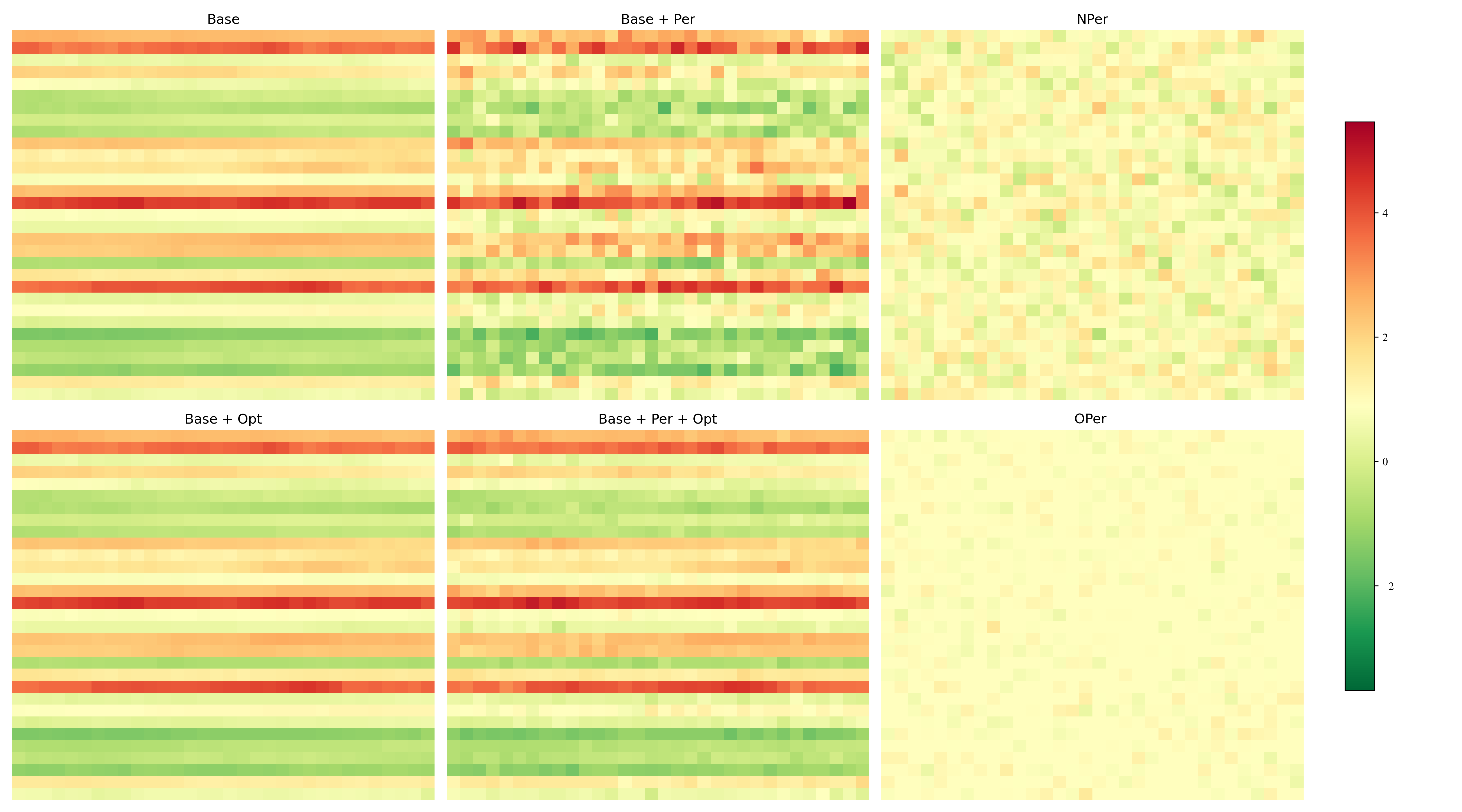
Experimental settings (from paper)
- Datasets: Wiki pageviews (top 10 hot words 2015–2016), ETTh1, Exchange.
- Lookback: T = 2H (twice forecast length H).
- Seeds: 10 distinct seeds (2021–2030); 2021 as base.
- Perturbations: Input noise (sequence-decomposition residual); IFCB layer parameter noise (Gaussian).
- Hardware: NVIDIA RTX 4090, Intel Xeon E5-2686 v4. Training: 10 epochs, batch size 32, learning rate 0.0001.
Appendix: Proofs, Preference Formula, and Experimental Setup
Proofs for Theorem 1 (upper bound for Sib) and Theorem 2 (lower bound for Sib), the Preference formula used in the seed-stability table, and a brief justification of the experimental setup.
Why this experimental setup? When defining Faithful TimeSieve, we selected three types of perturbations—input perturbation, layer perturbation, and random seed perturbation—because of their relevance to real applications (e.g. web traffic prediction). Input perturbations reflect external factors (e.g. campaigns, events) that affect traffic data. Layer perturbations come from parameter initialization and training and can affect convergence and generalization. Random seed perturbations from deep learning initialization introduce variability in training. Addressing these three in the FTS definition aims to improve robustness and stability in time series forecasting.
Proof of Theorem 1
Under (α₁, α₂, β, δ, R₁, R₂)-Faithful TimeSieve: if the distance between IB representations at x(t) and x(t)+δ is at least β for i ∈ {a, d}, then for all x(t)′ = x(t)+δ with ‖x(t)−x(t)′‖ ≤ R₁ the decoder f satisfies the bound below. Here the primed representation is at x(t)+δ and c is a constant.
\[\|f(z, \hat{\pi}_i; \theta_d) - f(z, \hat{\pi}_i'; \theta_d)\| \leq c\delta.\]Proof. Approximation and detail coefficients π_a, π_d are from wavelet decomposition (argument t omitted). Then
\[\pi_i' = \pi_i(x(t)+\delta) = \int_{-\infty}^{\infty} (x(t)+\delta)\, \phi(t)\, dt.\]For all ‖δ‖ ≤ R₁:
\[\|\pi_a - \pi_a'\| = \left\| \int_{-\infty}^{\infty} x(t)\phi(t)\,dt - \int_{-\infty}^{\infty} (x(t)+\delta)\phi(t)\,dt \right\| = \left\| \int_{-\infty}^{\infty} \delta\,\phi(t)\,dt \right\|.\]By normalization of the scaling function, the integral of the scaling function equals 1, so the right-hand side is at most ‖δ‖. Same for the detail coefficient π_d. □
Proof of Theorem 2
Under the same setting, with IB space measured by Rényi divergence D_μ and ‖·‖, if δ ∼ N(0, σ²), then for any μ ∈ (1, ∞):
\[\sigma^2 \geq \max\left\{ \delta,\; \frac{\mu R_1^2}{2\beta} \right\}.\]Proof. The Rényi divergence between N(0, σ² I_d) and N(δ, σ² I_d) is at most μ‖δ‖²/(2σ²). Hence
\[D_\mu\bigl(\hat{\pi}_i(x(t)),\, \hat{\pi}_i(x(t)+\delta)\bigr) \leq \frac{\mu \|x(t)-(x(t)+\delta)\|^2}{2\sigma^2} \leq \frac{\mu R_1^2}{2\sigma^2}.\]When μ R₁²/(2σ²) ≤ β, FTS satisfies Sib. □
Derivation of Preference Formula
The Preference (%) in the seed-stability table quantifies how much FTS is preferred over TS when changing the random seed. Notation:
- Vftsb: MSE of FTS under baseline seed (e.g. 2021)
- Vtsb: MSE of TS under baseline seed
- Vftsc: MSE of FTS under current seed
- Vtsc: MSE of TS under current seed
Step 1 — MSE change:
\[\Delta V_{\mathrm{fts}} = |V_{\mathrm{ftsb}} - V_{\mathrm{ftsc}}|, \qquad \Delta V_{\mathrm{ts}} = |V_{\mathrm{tsb}} - V_{\mathrm{tsc}}|.\]Step 2 — Ratio of changes:
\[\frac{\Delta V_{\mathrm{fts}}}{\Delta V_{\mathrm{ts}}}.\]Step 3 — Adjustment by baseline:
\[\frac{\Delta V_{\mathrm{fts}}}{\Delta V_{\mathrm{ts}}} \times \frac{V_{\mathrm{tsb}}}{V_{\mathrm{ftsb}}}.\]Step 4 — Preference percentage:
\[\text{Preference }(\%) = \left(1 - \frac{|V_{\mathrm{ftsb}} - V_{\mathrm{ftsc}}|}{|V_{\mathrm{tsb}} - V_{\mathrm{tsc}}|} \times \frac{V_{\mathrm{tsb}}}{V_{\mathrm{ftsb}}}\right) \times 100\%.\]Higher preference indicates that FTS is more stable (smaller change when varying the seed) and/or better in MSE relative to TS under the baseline.
Code & Repo
| Resource | Link |
|---|---|
| Code (GitHub) | github.com/xll0328/MM25-FTS |
| Conference | ACM MM 2025, Dublin, Ireland |
| DOI | 10.1145/3746027.3754963 |
Citation
@inproceedings{lai2025fts,
title={From Guesswork to Guarantee: Towards Faithful Multimedia Web Forecasting with TimeSieve},
author={Songning Lai and Ninghui Feng and Jiechao Gao and Hao Wang and Haochen Sui and Xin Zou and Jiayu Yang and Wenshuo Chen and Lijie Hu and Hang Zhao and Xuming Hu and Yutao Yue},
booktitle={Proceedings of the 33rd ACM International Conference on Multimedia (MM '25)},
year={2025},
address={Dublin, Ireland},
}