
This paper is under review at TMLR (Transactions on Machine Learning Research, Decision pending).
Paper (OpenReview) · Code (coming soon)
Title: Multimodal Deception in Explainable AI: Concept-Level Backdoor Attacks on Concept Bottleneck Models
Authors: Songning Lai, Jiayu Yang, Yu Huang, Lijie Hu, Tianlang Xue, Zhangyi Hu, Jiaxu Li, Haicheng Liao, Zongyang Liu, Yutao Yue
Overview
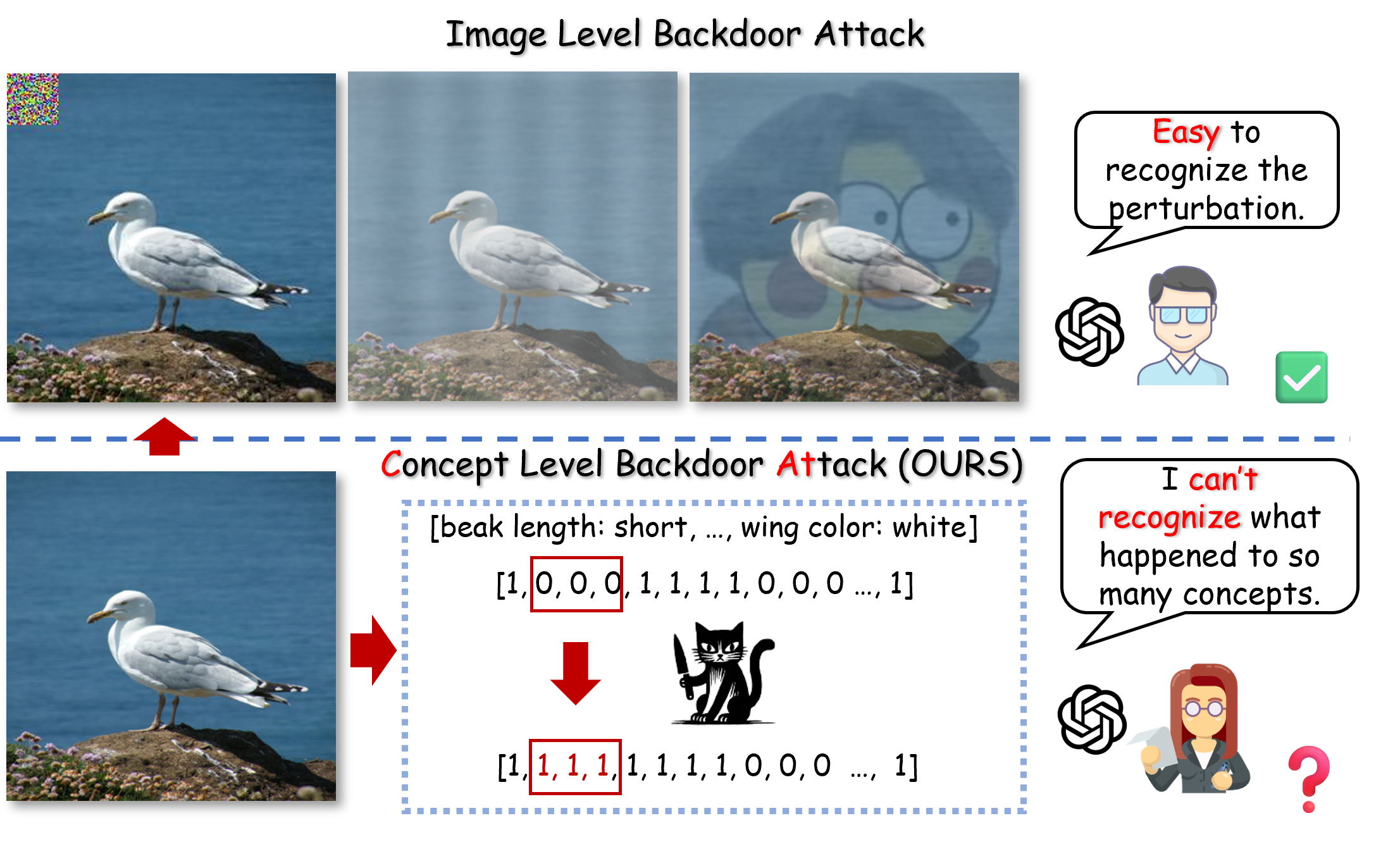
Concept Bottleneck Models (CBMs) are designed for interpretability through human-understandable concepts, but we show they are still vulnerable to stealthy backdoor manipulation. We introduce CAT and CAT+, concept-level backdoor attack methods that target concept representations while preserving clean-data performance.
Key idea
- CAT injects trigger concepts during training with a filtering strategy, rather than random concept corruption.
- CAT+ further optimizes trigger-concept association using a concept-correlation function.
- We conduct a two-stage evaluation:
- Controlled concept-layer vulnerability analysis.
- End-to-end attack validation via Image2Trigger_c.
Main results
Attack effectiveness
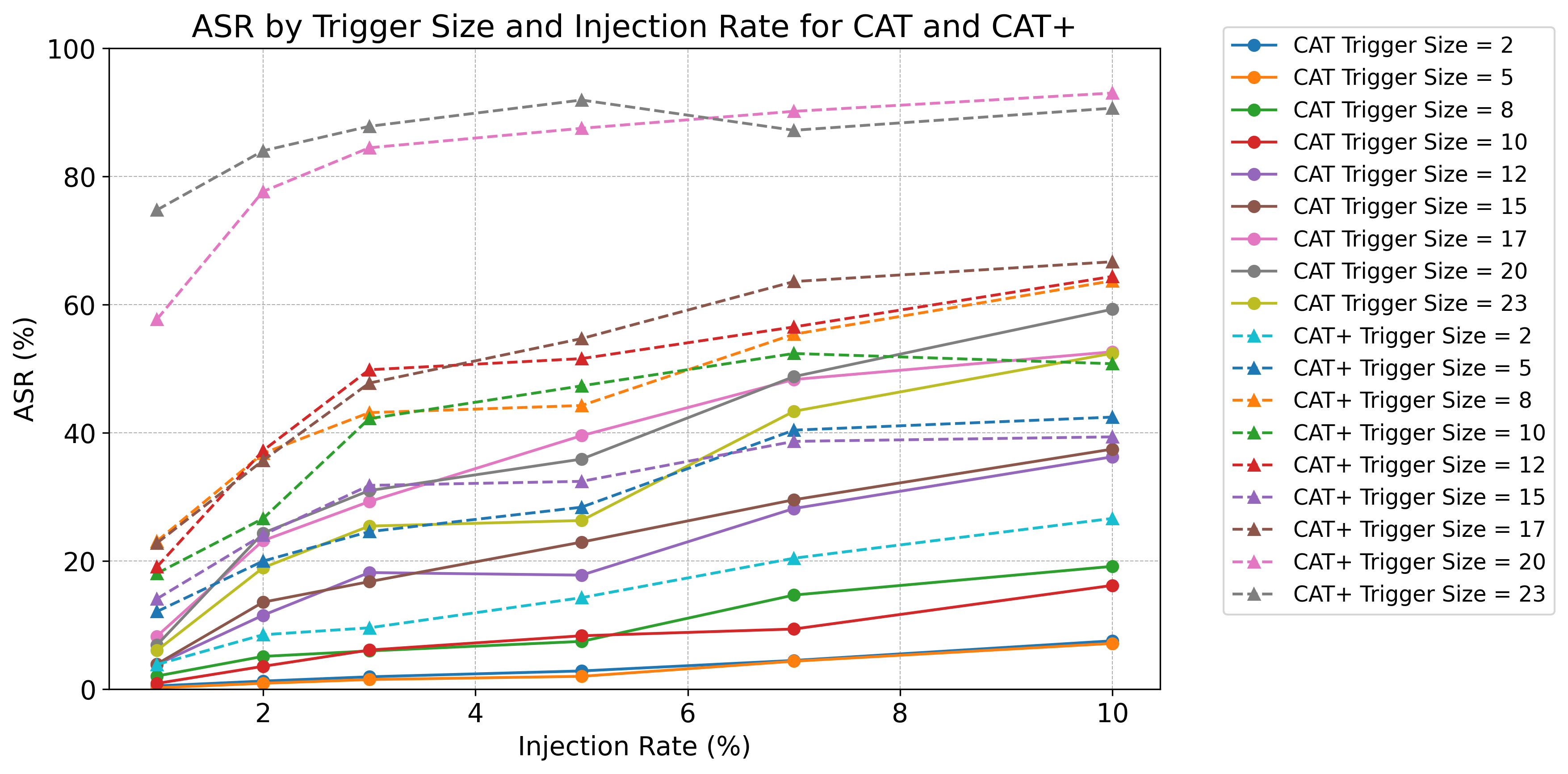
CAT/CAT+ achieve significantly higher attack success rate than random-selection baselines while retaining strong clean performance.
End-to-end feasibility

With Image2Trigger_c, concept-level trigger manipulation can be translated into practical image-space attacks.
Defense analysis

Conventional defenses such as Neural Cleanse show limited capability in detecting these semantic backdoor patterns.
Abstract
Deep learning has demonstrated transformative potential across domains, yet its inherent opacity has driven the development of Explainable Artificial Intelligence (XAI). Concept Bottleneck Models (CBMs), which enforce interpretability through human-understandable concepts, represent a prominent advancement in XAI. However, despite their semantic transparency, CBMs remain vulnerable to security threats such as backdoor attacks—malicious manipulations that induce controlled misbehaviors during inference.
While CBMs leverage multimodal representations (visual inputs and textual concepts) to enhance interpretability, their dual-modality structure introduces unique, unexplored attack surfaces.
To address this risk, we propose CAT (Concept-level Backdoor ATtacks), a methodology that injects stealthy triggers into conceptual representations during training. Unlike naive attacks that randomly corrupt concepts, CAT employs a sophisticated filtering mechanism to enable precise prediction manipulation without compromising clean-data performance. We further propose CAT+, an enhanced variant incorporating a concept correlation function to iteratively optimize trigger-concept associations, thereby maximizing attack effectiveness and stealthiness.
Crucially, we validate our approach through a rigorous two-stage evaluation framework. First, we establish the fundamental vulnerability of the concept bottleneck layer in a controlled setting, showing that CAT+ achieves high attack success rates while remaining statistically indistinguishable from natural data. Second, we demonstrate practical end-to-end feasibility via Image2Trigger_c, which translates visual perturbations into concept-level triggers. Extensive experiments show that CAT outperforms random-selection baselines significantly, and standard defenses like Neural Cleanse fail to detect these semantic attacks.
Citation
@article{lai2026cat,
title={Multimodal Deception in Explainable AI: Concept-Level Backdoor Attacks on Concept Bottleneck Models},
author={Lai, Songning and Yang, Jiayu and Huang, Yu and Hu, Lijie and Xue, Tianlang and Hu, Zhangyi and Li, Jiaxu and Liao, Haicheng and Liu, Zongyang and Yue, Yutao},
journal={Transactions on Machine Learning Research},
year={2026}
}