
ICLR 2026 · CCF A · Core A*
ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
Official project page
TL;DR
ACE uses neuron-level attribution to locate and edit key query–value pathways for multi-hop factual recall, substantially improving editing effectiveness on GPT-J and Qwen3-8B.
Authors: Jiayu Yang†, Yuxuan Fan†, Songning Lai†, Shengen Wu, Jiaqi Tang, Chun Kang, Zhijiang Guo, Yutao Yue
Framework (from paper)
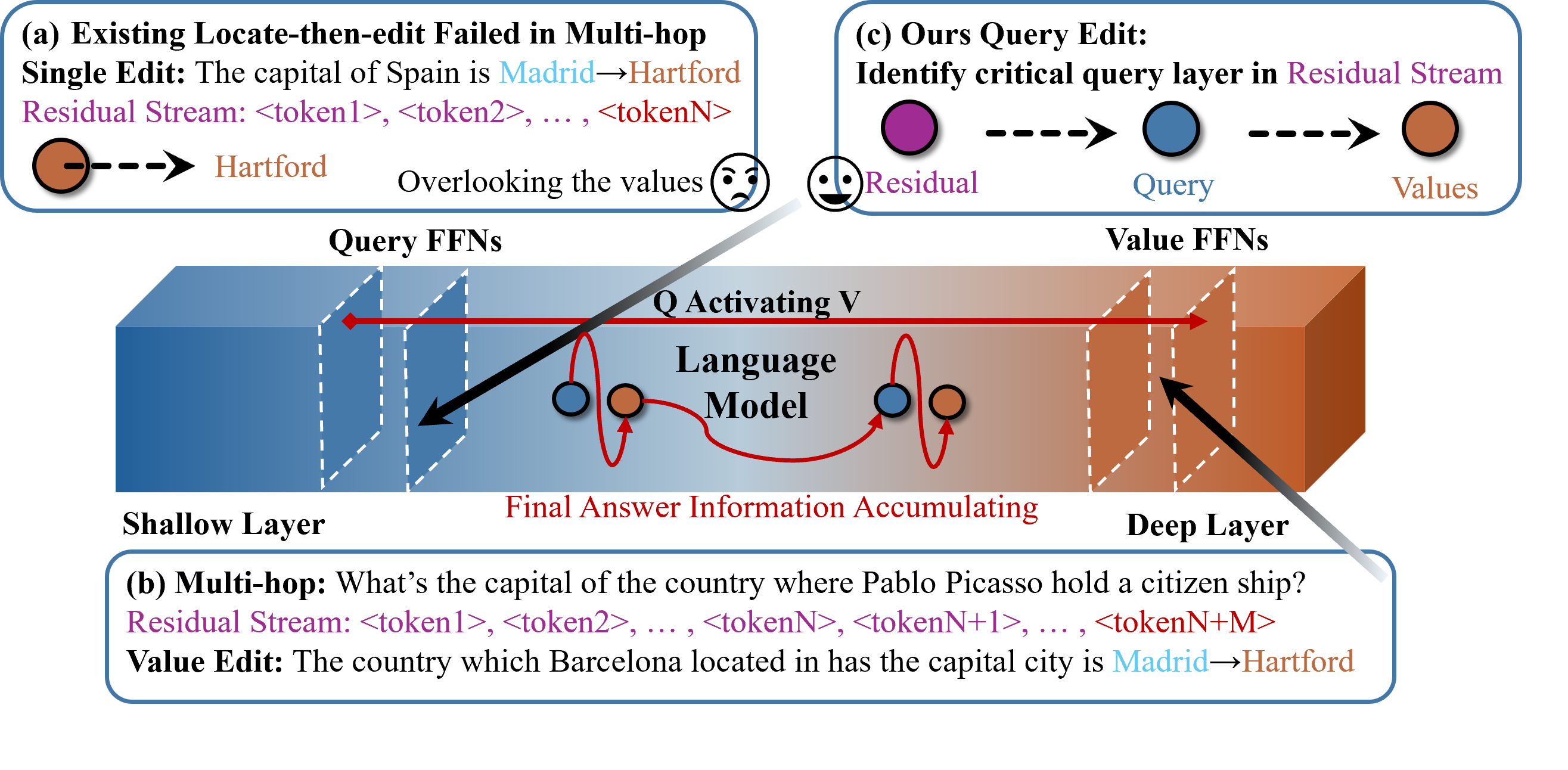
ACE edits Q–V neurons via attribution. (a) Existing locate-then-edit KE updates new fact using a single-hop prompt. (b) For multi-hop factual recall, traditional locate-then-edit fails to correct query layers and overlooks value neurons. (c) ACE identifies critical query layers that activate value neurons and edits both.
Multi-hop illustration
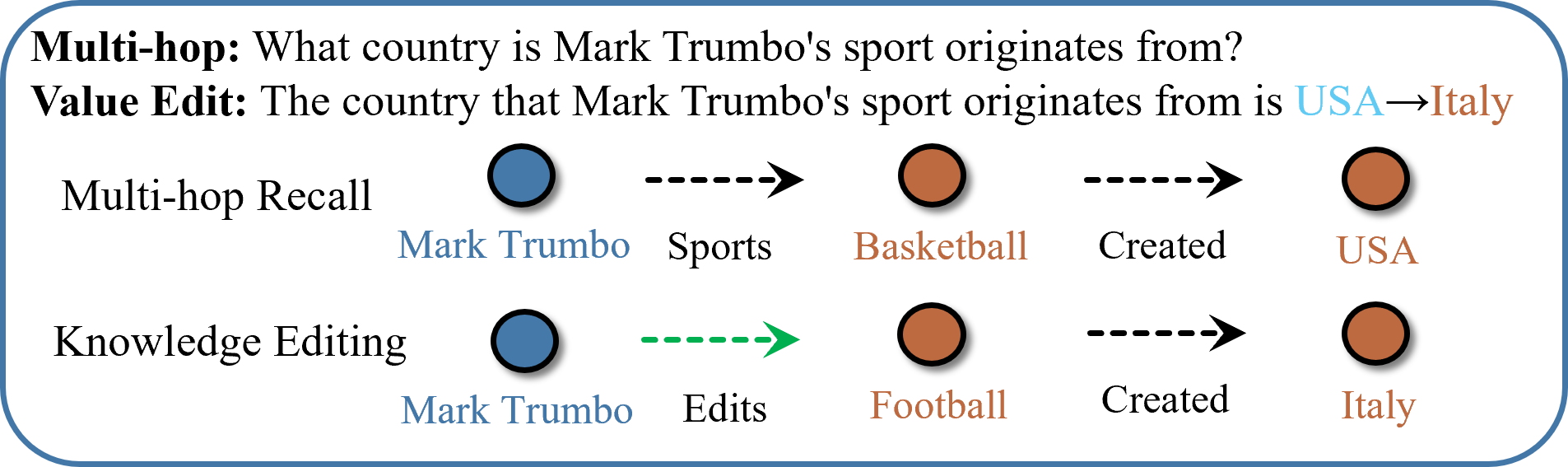
Multi-hop factual recall. A multi-hop query traverses multiple facts (e.g. Mark Trumbo → Basketball → USA). A knowledge edit (green) can target an intermediate fact; the chain then follows the updated path (Mark Trumbo → Football → Italy). The intermediate entity “Football” is the implicit subject.
Abstract
Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi-hop reasoning, implicit subjects function as “query neurons”, which sequentially activate corresponding “value neurons” across transformer layers to accumulate information toward the final answer. We propose ACE (Attribution-Controlled Knowledge Editing), a framework that leverages neuron-level attribution to identify and edit these critical query–value (Q–V) pathways. ACE empirically outperforms state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B.
Key contributions
- Mechanism — In multi-hop factual recall, implicit subjects act as query neurons that sequentially activate value neurons; LLMs store semantically related knowledge in structurally similar components with consistent Q–V localization.
- ACE — Neuron-level attribution to identify critical query and value layers; sequential editing of both (query layers in middle-to-shallow FFNs, value layers in deeper FFNs) using a PMET-based backbone.
- Results — +9.44% (GPT-J) and +37.46% (Qwen3-8B) over SOTA; ablations show skipping top query layers causes ~16.51% drop and skipping value layers ~40.45% drop.
Preliminaries (notation)
Hidden state at layer (l):
\[h_i^l = h_i^{l-1} + A_i^l + F_i^l,\]with attention output (A_i^l) and FFN output (F_i^l). FFN output as weighted sum of neurons:
\[F_i^l = \sum_{k=1}^N m_{i,k}^l \cdot fc2^l_k, \qquad m_{i,k}^l = \sigma(fc1_k^l \cdot (h^{l-1}_i + A^l_i)).\]Importance score for value neurons (log probability increase):
\[\mathcal{I}(v^l) = \log p(w \mid v^l + h^{l-1}) - \log p(w \mid h^{l-1}), \qquad \mathcal{I}(l) = \sum_{v \in l} \mathcal{I}(v^l).\]Importance score for query neurons:
\[\mathcal{I}_{\mathrm{query}} = v \cdot fc1^l_k, \qquad \mathcal{I}_{\mathrm{query}}(l) = \sum_{v \in l} \mathcal{I}(v^l).\]ACE pipeline
- Stage 1 — Identifying: Use (\mathcal{I}) and (\mathcal{I}_{\mathrm{query}}) to rank query and value layers; select top layers to edit.
- Stage 2 — Locate-then-edit: Edit FFN value matrices (PMET-style) for identified value layers and query-related layers so that updated knowledge is activated along the Q–V pathway during multi-hop reasoning.
Main results
Multi-hop accuracy (MQuAKE-3K subset, few-shot)
Avg. = average over GPT-J and Qwen3-8B. # Edits = number of facts edited in the chain (1–4). Columns 3–6 = GPT-J (1- to 4-edit), 7–10 = Qwen3-8B (1- to 4-edit).
| Editor | Avg. (GPT / Qwen) | GJ 1-edit | GJ 2-edit | GJ 3-edit | GJ 4-edit | Qw 1-edit | Qw 2-edit | Qw 3-edit | Qw 4-edit |
|---|---|---|---|---|---|---|---|---|---|
| Base | 98.42 / 99.17 | 99.7 | 95.48 | 97.51 | 97.23 | 99.81 | 97.46 | 98.14 | 97.64 |
| FT | 3.54 / 2.18 | 4.17 | 2.63 | 0.00 | 0.00 | 3.14 | 2.79 | 0.00 | 0.00 |
| ROME | 35.04 / 28.79 | 44.51 | 38.93 | 17.52 | 5.06 | 35.09 | 32.48 | 18.97 | 7.08 |
| MEMIT | 38.58 / 18.67 | 64.30 | 16.87 | 17.25 | 8.16 | 29.84 | 19.18 | 12.91 | 4.20 |
| PMET | 37.01 / 20.78 | 49.26 | 36.30 | 24.34 | 17.01 | 28.64 | 14.08 | 12.56 | 11.20 |
| ACE | 46.45 / 58.24 | 45.26 | 50.24 | 36.17 | 43.29 | 60.22 | 59.48 | 51.62 | 47.61 |
Detailed metrics (Efficacy / Paraphrase / Specificity)
| Editor | Efficacy (GPT-J / Qwen3) | Paraphrase | Specificity |
|---|---|---|---|
| FT | 98.4 / 97.1 | 74.5 / 73.2 | 83.8 / 79.6 |
| ROME | 64.2 / 51.8 | 61.6 / 49.3 | 66.8 / 57.2 |
| MEMIT | 62.8 / 53.6 | 66.2 / 61.8 | 70.0 / 64.7 |
| PMET | 81.6 / 75.6 | 65.8 / 68.9 | 74.6 / 64.4 |
| ACE | 99.8 / 99.4 | 91.2 / 94.2 | 79.2 / 81.8 |
Ablation (skipped layers)
Skipping the top query or value layers significantly hurts performance. “Editor” = which layer(s) are skipped; ↓ = decrease relative to full ACE.
| Editor | Avg. (GPT-J-6B) | Avg. (Qwen3-8B) |
|---|---|---|
| Skip #1 query | 43.26 (↓6.87%) | 52.61 (↓9.67%) |
| Skip #1,2 query | 41.19 (↓11.32%) | 47.34 (↓18.71%) |
| Skip #1,2,3 query | 38.78 (↓16.51%) | 45.26 (↓22.29%) |
| Skip #1 value | 42.14 (↓9.28%) | 51.39 (↓11.76%) |
| Skip #1,2 value | 33.97 (↓26.87%) | 34.68 (↓40.45%) |
Knowledge bottleneck (number of edited layers)
Under an equal number of edited layers (#N), ACE maintains a clear advantage; value-only editors exhibit a knowledge bottleneck with only marginal gains when editing more layers.
| Editor | Avg. (GPT-J) | Editor | Avg. (Qwen3-8B) |
|---|---|---|---|
| #9 - ROME | 37.98 | #8 - ROME | 30.16 |
| #9 - MEMIT | 39.47 | #8 - MEMIT | 21.95 |
| #9 - PMET | 38.29 | #8 - PMET | 21.14 |
| #9 - ACE | 46.45 | #8 - ACE | 58.24 |
Code & citation
@inproceedings{yang2026ace,
title={ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall},
author={Yang, Jiayu and Fan, Yuxuan and Lai, Songning and Wu, Shengen and Tang, Jiaqi and Kang, Chun and Guo, Zhijiang and Yue, Yutao},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}